- 为什么目前 PM 设计的 GPT 落地的形式都是 copilot?
- 为什么我不看好目前的 AutoGPT?
- 为什么目前不需要担心 GPT 替代人的工作?
- 比被 GPT 替代更可怕的是什么?
- AI 项目和产品设计时最需要考虑的是什么?
为了方便理解,下文中会用 GPT 来替代 LLM。同时所有试验均是基于 GPT4 完成。
GPT/LLM 落地的前提
完成多步任务
在 GPT 爆火出圈后,许多公司都开始围绕 GPT 研发应用,例如:法律文书的撰写和检查、代码的撰写和检查、自动客服、信息检索等等。而这些应用,基本都是需要进行多轮 GPT 的对话来完成的。
即使是最直观的写作助手里的功能,例如修改错别字、总结文章,如果要达到较好的效果,也需要使用多轮对话。假如我们使用 GPT4-32k 的模型,直接给 GPT 一段1万字的文章,让他找出其中需要修改的语病和错别字,无论实际有多少错别字,他大概率只会返回100-200字左右的回答。
这大概是由于在 GPT 进行 HFRL (Human feedback reinforcement learning) 阶段,使用的对话语料都不会太长,导致随着回答字数的增加,positional encoding 的编码随之变化,出现对话结束语的概率也随之增加。

那怎么克服这个 GPT 本身的问题呢?如果要实现最佳的效果,在不微调模型的前提下,需要把一个大的任务拆分成适合 GPT 完成的小任务,使得 GPT 能在他能力最强的范围内完成回答,最终再把结果组合起来。例如修改错别字的任务,一次性提供1万字的文章可能效果不好,但是拆分成1000字一段再用 GPT 分析,分析后组合起来的效果就好很多。这也是 AutoGPT 等项目的主要思路。
所以让 GPT 能成功完成多步任务,往往是产品落地的一个前提,但 GPT 成功完成多步任务的难度其实非常高。
完成多步任务的挑战
既然像 AutoGPT 已经能主动拆分任务,并各个击破了,产品落地还有什么困难吗?
答案是概率。
要知道,即使 GPT4 也并不能在所有小任务上保证 100% 的成功率。GPT 本质上还是机器学习模型,会根据当前信息选取概率最高的单词。这也意味着,如果运气不好,选取到了一个错误的单词,GPT 也只能顺着话往下说。例如让 GPT 总结一个文章,GPT 可能弄错了文章中词语的一个前后关系,那这个错误就不会变化了。
假如每一个子任务有 99% 的成功率,而一个父任务有 10个子任务,那么顺序执行父任务的成功率就只剩下 90% 了。而实际产品使用的过程中,90% 也许就意味着不可用。

那有什么办法可以解决这个问题吗?
尝试 + 校验
让我们回顾目前成功落地的产品,例如 Github Copilot, Chat GPT,在使用的过程中,往往会有这样一个交互的形态:

- GPT 生成一个答案/代码/操作。
- 用户会校验这个结果是否可用。
- 用户也许会直接采用这个结果,也可能重新让 GPT 生成尝试,也可能自己少量修改结果后使用。
这个交互形态的背后的逻辑包括:
- 生成答案是更费时费力的,但判断挑选是更轻松的,所以让 GPT 来生成答案,人来挑选,可以节约时间。
- 生成答案往往是不完美的,达不到可用的成功率,但是通过多次尝试,可以提高成功率。
既然校验的难度更低,那是不是可以让 GPT 来进行校验呢?这也是一些 prompt engineering 的技巧背后的思路:让 GPT 多尝试几次,再让 GPT 自己校验答案。这样一来每个步骤的成功率就被提升到与校验成功率相近了。

例如生成一个符合需求的文章标题成功率是 90%,但是校验文章标题是否符合需求的成功率是 99%,那么只要进行多次尝试,就可以接近 99% 的成功率完成这个任务。
这个思路确实可以提高 GPT 生成答案的质量,也是类似 AutoGPT 的项目火起来的基础。但是我仍然不看好当前阶段的 AutoGPT。
与人脑流程的对比
GPT 要自主完成多步任务,其实是在模仿人脑的逻辑思考和计划的过程。但是人在思考时,有许多隐含的思考流程是没有被识别出来的。我们拿修改润色润文章的这个简单过程来做个对比。
这个过程如果只用一句提示词 ”请修改润色这篇文章“,那么 GPT 的回答可能会出现下面的问题:
- 漏掉部分语句,因为 GPT 并不保证注意力机制会逐句分配。
- 识别出不需要改的字,并强行修改,使得语句更不通顺。
- 识别出了需要改的字,但是提供的修改不是最好的
换做人的思考流程来看,看起来只是人阅读一遍,然后一个个字修改,但隐含的思考可能包括:
- 一边阅读,一边一句一句地进行判断:
- 判断:这句话阅读起来是否通顺,是否有可能包含错别字?
- 识别:如果可能包含错别字,识别出错别字。
- 生成:根据识别出的错别字,生成用来替换的字。
- 重新判断:判断替换的字是否能阅读通顺,是否解决了错别字的问题。
- 潜意识判断:在行文风格和全文级别,这个修改是否合适。
- 判断:这句话阅读起来是否通顺,是否有可能包含错别字?

而人脑的思考并不是只做一遍的,其实是一遍一遍不停地循环的,而 GPT 其实只做了一最简单的生成。如果要达到与人脑相似的精度和可控程度,我们也需要让 GPT 不停地循环,从而保证 GPT 做出的每一个操作都是高成功率的。
而让 GPT 不停循环,并不能保证在一定循环数量内达到目标效果,假设回复一个客户需要10分钟的时间来循环生成答案,这个在时间和调用 API 的成本上都是不可接受的。
为什么产品设计形态以 copilot 为主
从前面的分析,我们可以得出,对于一个任务来说,GPT 对一个任务的完成度可能是 60%,后续每提升 10% 的完成度可能就需要额外的几倍成本。
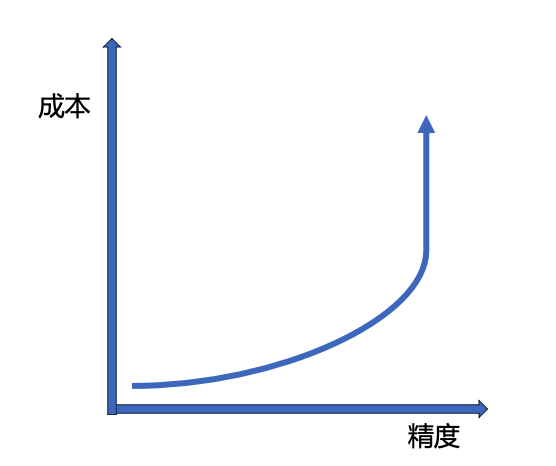
所以现在最多的产品形态就是 copilot,用人脑的判断能力来解决 LLM 在精度和可控程度上的不足。
为什么我不看好目前的 AutoGPT
同理,AutoGPT 的愿景很美好,但是也决定了,高成功率,高精度和低成本之间是不可兼得的。
- 如果让 AutoGPT 自动化复杂的事情,操作的步骤数可能会很多,也就很难保证正确性。而一些操作在没有 100% 正确性的前提下,是不能使用的,比如购物、订票、法律建议等等。
- 如果让 AutoGPT 做简单的事,步骤数较少时,价值往往也不大。就像 Siri 一样。
从商业化的性价比出发,我认为 AutoGPT 的形式目前来说并不合适。这也是为什么我认为不需要担心 GPT 替代人的工作。
未来的发展方向
对比人脑的思考方式和 GPT 的使用方式,可以看出来 GPT 对生产力的提升主要在于一次生成内容的成本上。
- 原模式:人进行多次循环的思考,生成一个高可控高精度的答案。
- GPT模式:GPT 单次推理,生成一个可控度低,质量有起伏的答案。由人选择质量高的答案采用。
进一步全自动化的难点就在于可控性。我觉得最主要的优化方向就是通过垂直场景的训练集微调或者蒸馏。类似于熟能生巧的方式,用足够多的训练集微调模型,使得不需要多次循环也可以生成更高精度高可控的答案。
而在准备训练集的过程中,可以用 copilot + 人类识别的方式来提高生产力,同时累积数据集。这个也类似于 Midjourney 的模式,先通过免费让大众使用,来获取人类的偏好数据,从而利用人类的打分不断提升模型质量。
比被 GPT 替代更可怕的是什么
在未来,我们可能会看到 GPT 和人类不断合作,人类扮演类似数据标注员的角色,为模型生成的内容提供反馈,挑选出适合使用的内容。
而人在这个过程中,就如同一块块电池,给 GPT 提供养料,让 GPT 不停积累数据,提高能力,最终完全替代某些人类的工作。就像黑客帝国中,人虽然还存在,但引以为傲的创造力,智慧,甚至尊严,都被无情地剥夺了,成为了无意识的数据提供者。

这是一种深深的讽刺,也是一种残酷的真实。我们自己创造出来的工具,却在资本逐利的驱使下,蚕食我们存在的意义。