背景
之前看过一本书,叫 《Algorithms to Live By: The Computer Science of Human Decisions》。讲的是在计算机科学中用到的一些算法,比如排序、缓存,在日常生活中也可以对我们有很多启发。我最近在看的 《Reinforcement Learning an introduction》(强化学习导论),其中提到的很多概念也能映射到我们的生活中,就在这里记录下来。
强化学习的问题假设非常贴近于日常的生活,强化学习是为了训练一个智能体,在一个环境中做出正确的决策,从而最大化收益:例如训练一个扫地机器人,在房间里,用最短的时间扫掉尽量多的灰尘。而我们在日常生活中也像一个个智能体,在这个社会里,想要最大化我们的个人价值。
失败是探索中的必经之路
在训练强化学习的智能体时,我们会让智能体不断尝试各种行为,从而让他学习到在不同环境下,每个行为的期望收益 (expected reward),从而让他建立起对每个行为的正反馈或者负反馈。这也意味着,在训练的过程中,智能体除了会收到正反馈,也一定会会收到很多负反馈。吸收负反馈,从而避免错误的选择,也是学习过程中很重要的一环。

在我们平时的生活中,对失败或者错误,总会有本能的抵触。当听到别人的批评或者否定意见,例如 ”你这个方案不太靠谱,没考虑到xxxx“,我们总是会本能地心跳加速,想要极力反驳:”不,是你没理解xxx“。但如果是强化学习的智能体,它就不会有任何抵触,它会将其作为人生经历的一部分,吸收它,从中学习到之前动作的不足之处。如果我们把收到负反馈作为我们必然会经历的事情,也许就能更坦然地面对,我们可以想象自己是一个正在学习的智能体,收到了负反馈之后尝试吸收它,通过逻辑思维来抑制住不理智的本能,这样我们也可以更真诚冷静地面对批评和质疑。

甚至,现在我特别希望能收到客观、有建设性的批评,那意味着我可以有更多提高的机会。
带着概率思维看结果
在强化学习问题的假设中,往往会使用期望收益 + 概率分布的方式来表示环境给智能体的反馈,例如扫地机器人选择往看起来有灰尘的方向走去,但是走到时那有一定概率会发现所谓的灰尘只是地砖的图案。即便智能体选择了一系列期望收益很高的动作,但是由于环境给智能体的反馈是带有随机波动的,可能最终的收益并不高。但只要重复的次数足够多,在大数定律下,平均收益总是会向期望收益收敛的。

在我们平时的生活中,可能也会出现这样的情况,我好像做对了所有的事,但是结果还是令人失望。例如我平时规律健身、健康饮食、早睡早起,但还是会得肠胃炎。即使从飞资助了上百名贫困地区的孩子,在他生命的最后时刻,还遭受到了被他资助过的人的质疑和无视。就像强化学习的环境一下,我们所处的世界也不是一个确定的世界,它处处都充满了混沌和随机,我们总能找出几个例子,说明北大毕业了也可能去卖猪肉,小学毕业也可能发大财,天天健身也可能得癌症,抽烟喝酒也可能长命百岁。但在大数定律下,我们的每一天都像一个掷骰子的回合,只要掷骰子的回合足够多,总是会向期望值靠拢的,北大毕业的平均收入总是比小学学历的高一些,规律运动的人群平均寿命总是比烟酒不断的人群长一些。
想明白了这一点,在面对极端情况时,我们可能稍微平和一点地看待它,尽人事听天命。
- 考试没考过,只要学到了扎实的知识,只是多考一两次的问题,迟早能过的,不用太沮丧。
- 辛苦准备的客户没谈成,只要产品够硬,迟早会有能匹配的客户,不用着急。
价值观的区别是来源于所经历的事有所不同
接着上一条,在强化学习中,由于环境有一定的不确定性,即使在同样的参数下训练出来的智能体,只要随机种子不同,那么有的会表现得特别好,有的会表现得特别差,甚至可能会有一些极端的智能体策略。

对我们来说,有的价值观区别是不可调和的,比如 好人没好报 vs 好人有好报,之所以会有这样的价值观区别,一定是他们过去经历的事情不同,看到、得到的反馈不同导致的。就如同之前大家都说的,“永远不要随意评价别人,因为你不知道别人经历了什么”。这也是我认为微软的 inclusion 文化是促进其全球化合作的一个关键点。接纳人和人之间的不同,这些不同未必有优劣之分,带着包容的眼光去尝试合作,会发现每个人都有想要把事情做好的初心。
好奇心创造更多可能
Explore vs Exploit 是强化学习中关键的 trade-off。Exploit 是指在当前已知的信息中,选择最好的一个选项。而 Explore 则是指即使我们知道了最佳的选项是什么,仍然尝试去选择其他的选项,从而验证其他的选项会不会有更好的 reward。从训练结果来看,在训练初期,Explore 会使得短期内的收益下降,但是会使长期的收益上升。因为 Explore 可以让智能体尝试更多可能,从而了解到各选项内更准确的期望收益,在后期的选择中,更容易选择到 真正的 最佳选项。
映射到我们的日常生活中,在我们刚到一个新环境时,也可以保持好奇心,多尝试。例如
- 刚到一个地方时,可以多尝试不同的餐厅,说不定能找到自己更喜欢的
- 刚开始工作时,可以多尝试多了解不同的工作类型,找到最能发挥自己能力和热情的职业,这样后期就能准确地选择对自己最有利的职业道路。
- 刚开始运动时,可以多尝试不同的运动方式、时间、地点,找到最适合自己生活习惯的运动,适合他人的未必适合自己。
- 刚开始相亲时,可以多尝试见见不同类型的对象,找到最适合自己的类型。
此间最难的也许是如何面对失败,面对失败时的心态很容易影响好奇心,所以最好带着概率思维去尝试。
学习的方法是知识积累的一阶导
在强化学习中,对 reward 的设置会直接影响到训练出来的智能体的行为,就像管理学中说常的:You get what you measure。例如我们如果对一个扫地机器人设置的 reward 是以电量占大比例,则可能它就会学会待在充电桩附近,而不出去寻找要扫的地方。而如果对收集到的垃圾占大比例,它甚至可能会自己打翻垃圾桶,从而多扫一些垃圾。
在最近几年 “鸡娃” 的讨论中,我一直有个观点,就是对孩子的关注点就是我们对孩子设置的 reward。如果我们关注的是在每一次考试或者比赛中拿奖,那通过参加各种补习班,是可以实现的。但这样的结果可能是在没有补习班的领域,就无法有所建树,因为孩子没有养成自主学习的方法。例如在前沿的研究领域,在工作或者创业的时候,没有人有标准答案,这时候没有好的学习方法,可能就会手足无措。但如果我们的关注点是在提高 学习方法 上,例如怎么在最短的时间内,找到相关的资料,怎么把相关的资料理解内化。这样一来,即使短期的成绩并没有提高,但学习的方法是知识积累的一阶导,只需要有足够的时间,就能把成绩提高。

以学习的方法作为 reward,就意味着当学习方法提高时,要给予正反馈,当学习方法降低时,要给予负反馈。例如:
- 不鼓励通过熬夜、死背代码等方式短期提高一部分的成绩。
- 即使短期成绩没有提高,但每日所需学习时间减少了,也是值得鼓励的。
成为时间的朋友
在强化学习中,智能体的学习训练,往往需要很多个回合,根据状态空间和算法的不同,几十万次也是很正常的。在刚开始时,甚至会觉得这个模型和算法是不是没办法收敛,表现一直在不稳定地波动。这可能是它还在积累原始经验的阶段,只要训练够次数,还是能收敛并提高效果的。
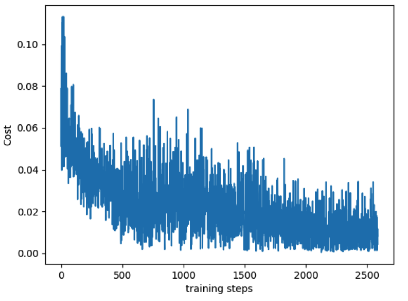
自从罗振宇先生的“时间的朋友跨年演讲”之后,“时间的朋友”也越来越火。很多细小的习惯可能是微不足道的,例如上楼不坐电梯,通过爬楼梯来完成零碎时间的锻炼,或者日常记录下自己的读书笔记。他们可能在一天两天的时间段内,不能给你明显的帮助,但是在坚持1年、2年、3年之后,回头看时,会发现身体状况或者知识积累已经比之前好了许多。我们的习惯的改变就像智能体的训练一样,刚开始微小的习惯提升可能微不足道,但在时间的加持下,会有明显的改变。
同样的,前面提到的很多道理都很简单。所谓知易行难,也许是我们还没有在生活的一个个回合中,把他们内化吸收,只要每天都能有一点吸收和提升,剩下的就交给时间好了。
最后
强化学习和人的学习和生活真的很像,可以触类旁通:看看自己如果作为智能体,训练的方法对不对,reward 设置是不是合理。
现在才开始看到强化学习导论的 tabular solution methods,希望后面还能有更多收获。