起因
在上一篇博客里,我提到了一个众包数据集的项目,是我作为 AI School 的项目贡献给 Qlib 社区的。这篇博客大概记录一下我做这个项目的动机、过程、未来的计划以及 Dolt 的选型经验。
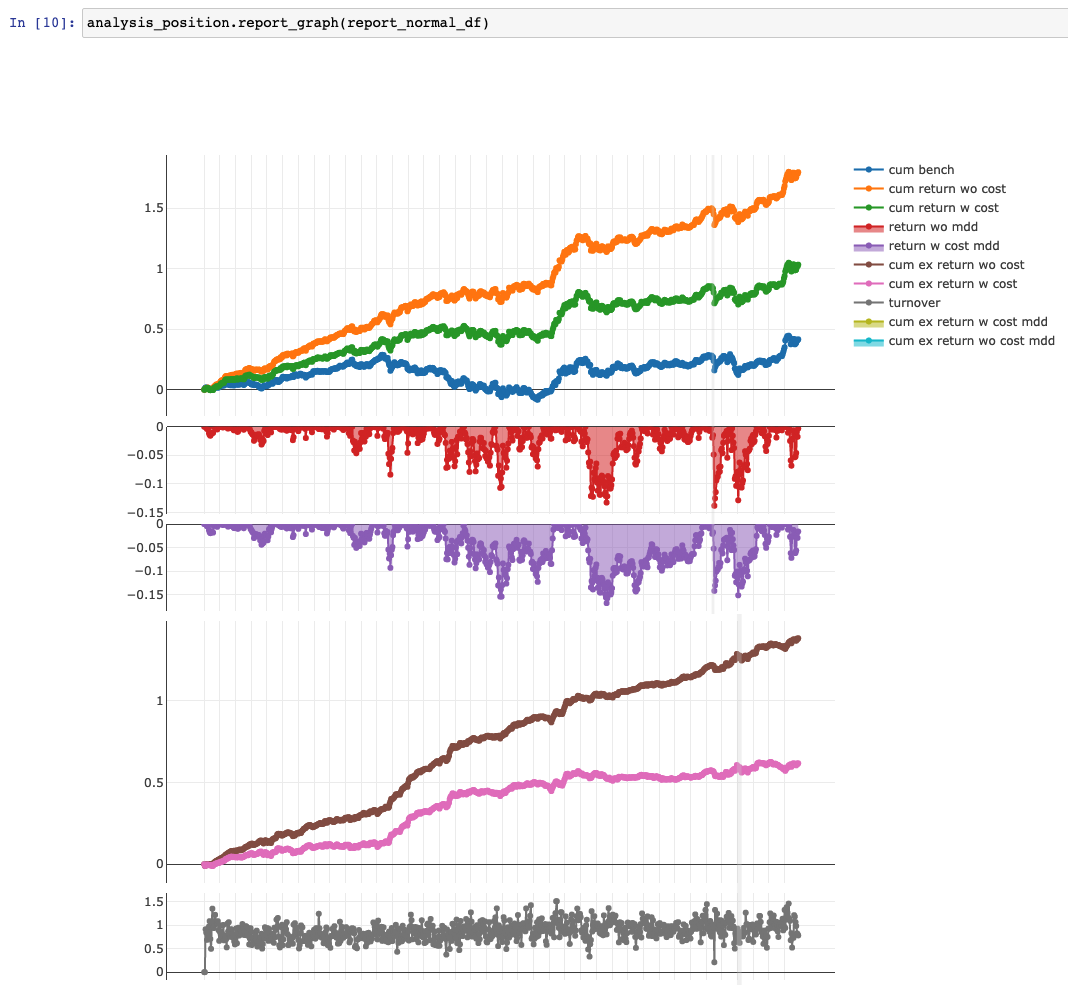
在尝试了 Qlib 的示例代码之后,Qlib 的回测结果显示在 2017 - 2020 年间的回测年化扣费超额收益可以达到 10% 以上。
我下一步好奇的便是:如果把这个模型在 2021、2022 年投入实盘的话,这两年的效果如何?
默认的 Qlib 数据集只提供到 2020 年,所以我便希望能更新数据到 2022 年,延长回测时间。但是我发现这个数据集要更新会遇到许多问题,于是便做了众包数据集的项目,也受到了 MSRA 老师的认可,拿到了项目二等奖。

Qlib 默认数据集的缺陷
数据更新方案
Qlib 的 A 股数据集来源经过 3 个阶段:
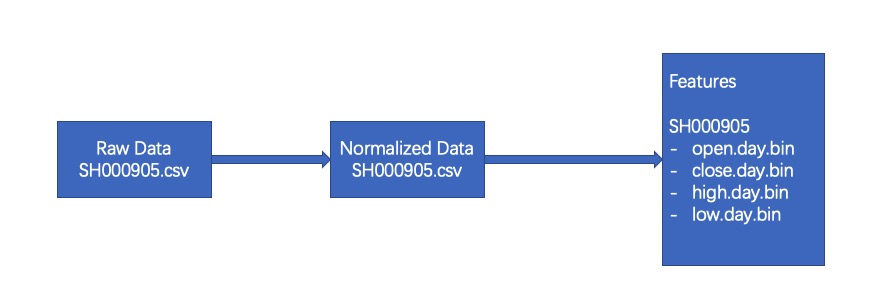
- 第一个阶段是爬虫将每个股票的日度量价数据采集下来,每个股票作为一个 csv 文件。
- 第二个阶段是处理这些 csv 文件,使得价格等数据归一化并复权,存成新的 csv 文件。这一步是不可逆的,因为归一化之后所有股票的第一日价格都是 1,我们无法得知原本的股价是多少。
- 第三个阶段是将归一化后的 csv 文件转成 numpy 格式的 bin 文件。
如果要从数据源进行更新,就需要将获得第一阶段中生成的 csv 文件,然后在原始 csv 上添加新数据后重新进行第二阶段的复权和归一化。由于第一阶段的数据并没有提供,项目自带的更新脚本便行不通了。
我尝试从头爬取所有股票数据,然后对数据重新进行一遍处理。但这时又发现了一些其他问题。
Yahoo Finance 数据源质量问题
Yahoo Finance 的数据本身质量不高,表现在几个方面:
- 000905.SH 应该是中证 500 指数,但是名称却是 000905.SZ 的厦门港务,类似的情况也发生在 000903.SH 等其他指数上。
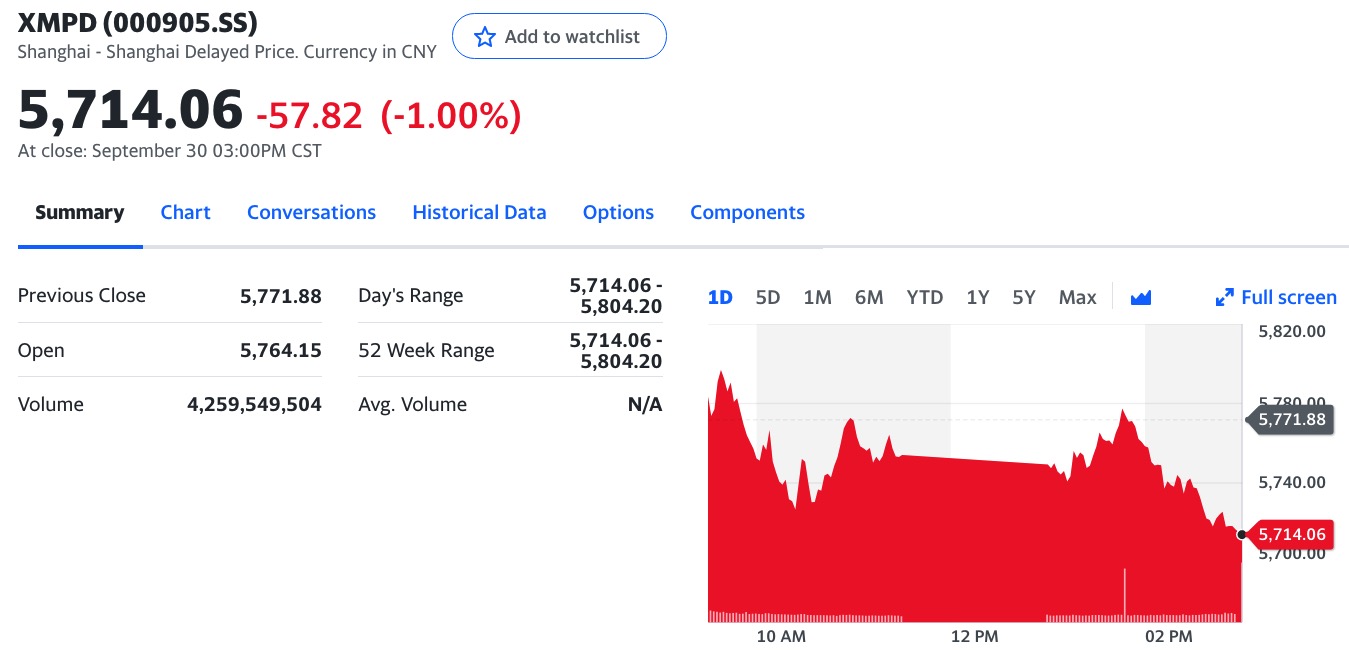
- 指数数据的历史数据缺失,例如 000905.SH 的历史数据只能获取到当天的。

- 缺少成交额数据。历史数据中的 Volume 对应的是成交量,但没有成交额数据。这就导致无法计算当日的平均成交价 (vwap)。
- 缺少京交所数据。
- 缺少退市股的数据。这点尤其重要,缺少退市股数据会导致回测时的幸存者偏差。因为无法走出的困境的企业都退市了,那么回测时困境反转类的策略就会表现特别好。
我也不确定数据的数值是否是正确的,为了能进一步避免数据数值上的错误,我们最好能利用多个不同的数据集进行交叉验证。
中证公司附件损坏
Qlib 的指数成分股数据是通过爬取中证公司的公告生成的,每个指数的成分股变更时,公告中会有 excel 文件记录变更的股票和权重。
但是由于部分公告的附件链接损坏,已经下载不到当时的 excel 了,所以原来的爬虫脚本也不能直接生成成分股变更数据。
为了能获得持续更新的指数成分股数据,我们只能从其他途径获取到历史的变更信息,然后再从公告信息中下载最新数据进行合并。
数据领域的重复劳动
类似上述的数据源质量的问题并不是我一个人会遇到的,但为什么每个遇到的人都要解决这样的问题呢?
在数据领域,即便是公开数据,例如国家统计局发布的 GDP、人口数据,股票数据,或者财报数据,都有可能会有数据错误,也都需要做数据的校验。即便是我们购买了商业数据库,我们可能也会对其中的数据质量产生质疑。
目前在数据校验的方式主要还是以 SQL 为主,但是整个过程却有一些不太科学的地方:
- 数据校验的过程无法回溯。如果校验的过程中有错误,例如比较错了时间,用错字段,很难回溯。少部分项目会用 git 对 sql 进行版本管理,大部分项目的数据校验 sql 就是一次性的。
- 数据是否经过校验,无法标注出来,使用者需要自行判断,并且重复校验。数据校验也是非常消耗算力的事情,但是我们拿到一个数据集的时候,没办法判断它做过什么样的校验,质量如何,这时候每个要用的人都需要对它进行一次校验。
- 部分异常值需要手动维护时,难以留存维护记录。例如某个爬虫脚本爬取到的数据有一条出错了,只能手动进行了修改,但是其他人拿到数据时,是没办法判断是不是做过这类手动维护修改的。
借鉴代码开源的思路,公开数据理应也可以用开源的方式来维护,使得数据的校验、维护工作不需要人人都做。
解决方案
为了解决 Qlib 的数据持续更新问题,我决定发起一个众包金融数据的项目。由我提供初始版本的数据,并做一些基础的校验。后续如果开源社区有兴趣提高 Qlib 的数据集,或者导出作为其他项目的数据集,都可以节约一些时间。
这个方案由两部分组成,Git 和 Dolt。Git 大家都比较熟悉,是代码的共享和版本管理工具。而 Dolt 则是数据的共享和版本管理工具,Dolt is git for data。
Dolt 介绍
Dolt 的特点在于两个:
- 提供兼容 SQL 的操作接口。
- 提供类似 Git 的版本管理语义。
举个几个例子就好理解了:
创建一个 Dolt 数据库
我们首先可以把它当作一个 SQL 数据库来用,类似 git init 一样先初始化一个 dolt 数据库:
% dolt init
Successfully initialized dolt data repository.
导入数据
Dolt 支持 csv 格式的数据导入,数据导入可以创建一个新表,也可以导入到一个已有的表中。这里我将 A 股的 csv 格式数据导入:
% dolt table import -c -pk=a_stock_eod_price_id a_stock_eod_price.csv
Rows Processed: 1700000, Additions: 1700000, Modifications: 0, Had No Effect: 0
Import completed successfully.
如果是导入到一个新表,Dolt 会自动根据字段的内容分析并设置对应的字段类型,这个流程和 Spark 导入 csv 数据有点像。
修改数据
Dolt 也支持用 sql 语句修改数据:
% dolt sql
# Welcome to the DoltSQL shell.
# Statements must be terminated with ';'.
# "exit" or "quit" (or Ctrl-D) to exit.
a_stock_eod_price> update a_stock_eod_price set update_time = '2022-01-01';
Query OK, 1700000 rows affected
Rows matched: 1700000 Changed: 1700000 Warnings: 0
a_stock_eod_price> exit
Bye
提交数据commit
和 Git 类似,Dolt 也可以添加数据的 commit,通过 commit 的方式来记录数据的修改原因:
首先用 status 命令查看修改过的表有哪些:
% dolt status
On branch main
Untracked files:
(use "dolt add <table|doc>" to include in what will be committed)
new table: a_stock_eod_price
然后用 add 命令添加修改过的表到修改历史中:
% dolt add .
% dolt commit -m "Add initial stock data"
commit b1aa1bbkvlblnasohleec9ga9pieo9ts
Author: Di Chen <chenditc@gmail.com>
Date: Mon June 06 17:58:06 +0800 2022
Add initial stock data
通过 log 命令查看数据的修改历史:
% dolt log
commit b1aa1bbkvlblnasohleec9ga9pieo9ts
Author: Di Chen <chenditc@gmail.com>
Date: Mon June 06 17:58:06 +0800 2022
Add initial stock data
commit b1aa1bbkvlblnasohleec9ga9pieo9ts
Author: Di Chen <chenditc@gmail.com>
Date: Mon June 06 17:20:06 +0800 2022
Initialize data repository
有了历史之后,我们甚至可以查看某条数据的某个 cell 是被谁在哪个 commit 修改的,比如我们想知道 SH000905 的数据被哪些 commit 修改过:
SELECT diff_type, from_commit, from_commit_date, to_commit, to_commit_date
FROM `dolt_diff_a_stock_eod_price`
WHERE `symbol` = "SH000905"
ORDER BY to_commit_date DESC
其中 dolt_diff_<table name> 就是指代某张表的更改历史,通过这个机制,我们可以回溯所有数据的增删改历史。
整体流程
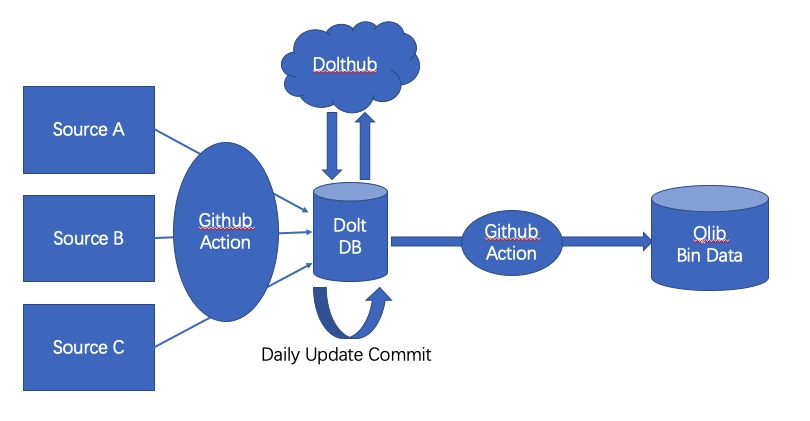
基于 Dolt,我提交了从不同数据源爬取到的 A 股数据,同时用 dolt commit 保存了我的校验过程。我目前做的校验还比较初步:
- 校验了 A 股历史数据的全量性,通过不同数据源的交叉验证,尽量补齐了所有股票的历史数据。
- 校验了 A 股历史数据的高开低收等价格的绝对值。如果两个数据源都有某个股票的数据,则找到价格不同的部分,选择在多个数据源里出现次数多的那个作为正确价格,如果差距不大,则不做修改。
- 校验了 A 股历史数据的复权因子。由于浮点数的精度问题,如果相差不大,则不作调整,如果相差大,则找对应的分红或者除权公告进行计算。
在校验之后,输出到最终的导出表中,提交到 Dolthub 上。Dolthub 是类似于 Github 的数据集托管平台。
Dolthub 提交历史可以看到每日的数据更新:

Dolthub 的提交 Diff 可以看到具体更新的内容:
校验过程中用到的 sql 语句和代码则托管在 Github 上,尽量让过程可以回溯。
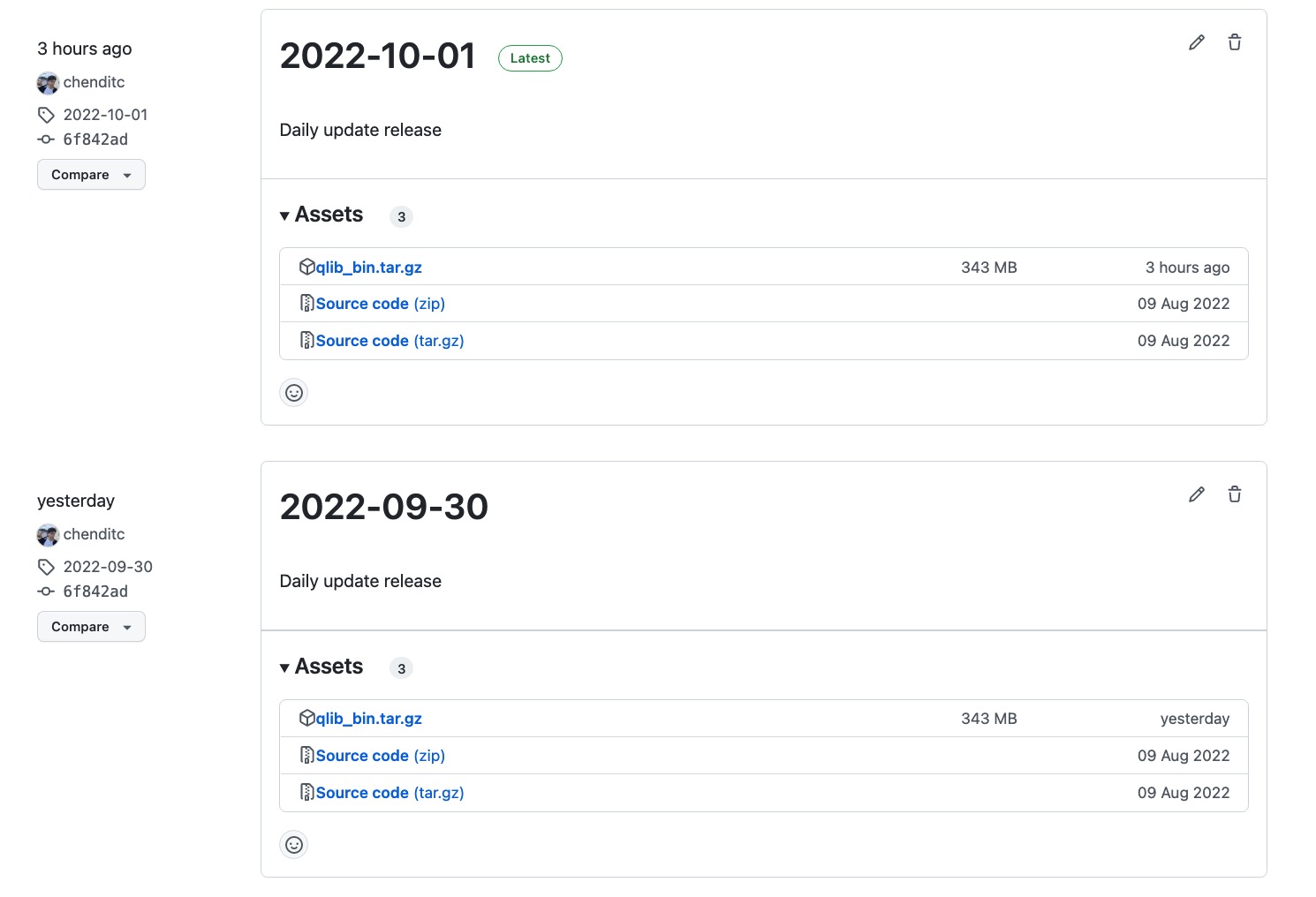
最后我设置了一个 Github Action,每日从公开数据集导入数据,并导出 Qlib 格式的 bin 文件,打包成 Artifact 上传到 Github 上。这样一来,如果有 Qlib 最新数据需求的同学,只要一行命令下载解压最新的 Github Release 即可。
$ tar -zxvf qlib_bin.tar.gz -C ~/.qlib/qlib_data/cn_data --strip-components=2
未来计划
这个项目还有很多没做完的事情:
- 更细致的校验。比如股票数据的全量性,除了不同数据源的交叉验证,还可以通过交易所的公告和公司财报进行确认,如果交易所公布某家公司的上市日期是 2001年,但是历史数据是从 2003 年开始的,那么显然少了2年的数据。
- 持续校验和自动修复。目前的校验只针对历史数据跑了一下,但是没有对日度更新的数据进行校验。理想状态下应该每日更新数据的时候都进行校验,同时根据一定规则选取我们认为更 “正确” 的数据进行更新。
- 数据校验算法和性能优化。目前的校验主要是通过 SQL 语句来实现的,部分操作例如多表的 Join 和聚合统计比较慢。最好可以进行优化一下,从而部署到 Github Actions 之类的 CI 平台,利用平台算力进行每日校验。
- 接入更多公开数据源。这是希望可以尽量避免单数据源导致的单点失败,减少数据错误和更新延迟的风险。
上面几个方面我一个人没有足够的精力完成,所以如果有同学希望做一些 side project 的,欢迎一起提交 PR 贡献。
如果只是想用最新的 Qlib 格式数据,可以到 Github 上下载:https://github.com/chenditc/investment_data/releases
初心:Qlib模型近两年的表现
我最开始的时候是为了检验 Qlib 模型在近两年的表现如何,这里顺便分享一下回测结果。
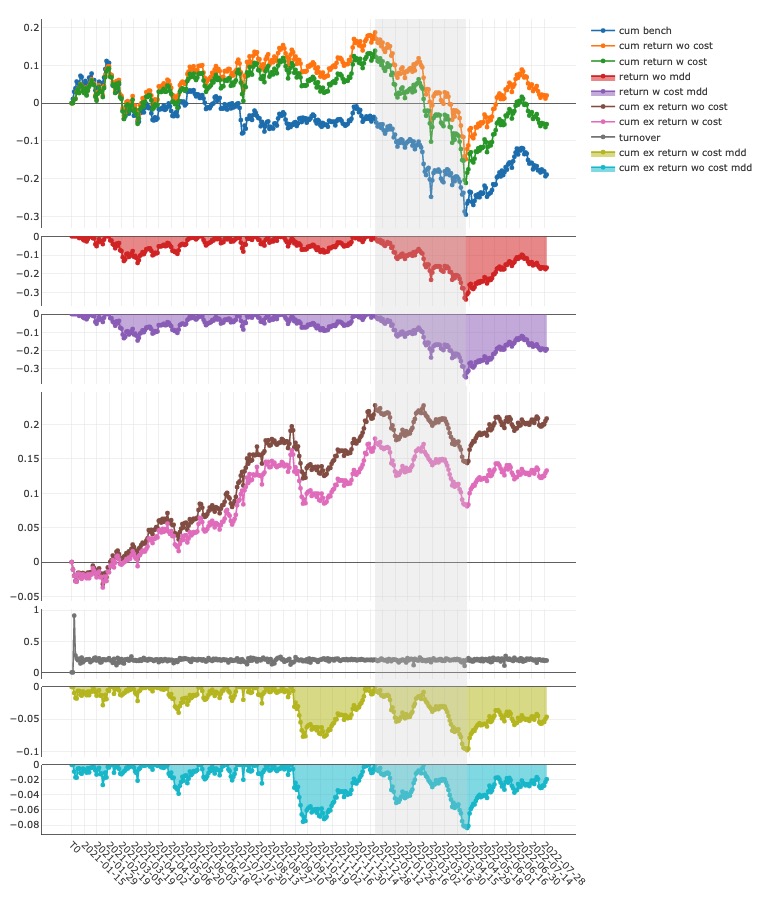
延长回测时间后发现,默认的 GBDT 模型在 2021.01.01 至 2022.08.01 模型在沪深 300 的股票池上仍然可以提供 13% 的无费率年化超额,8% 的扣费年化超额:
'The following are analysis results of the excess return without cost(1day).'
risk
mean 0.000547
std 0.006281
annualized_return 0.130104
information_ratio 1.342765
max_drawdown -0.083978
'The following are analysis results of the excess return with cost(1day).'
risk
mean 0.000348
std 0.006282
annualized_return 0.082902
information_ratio 0.855439
max_drawdown -0.098453
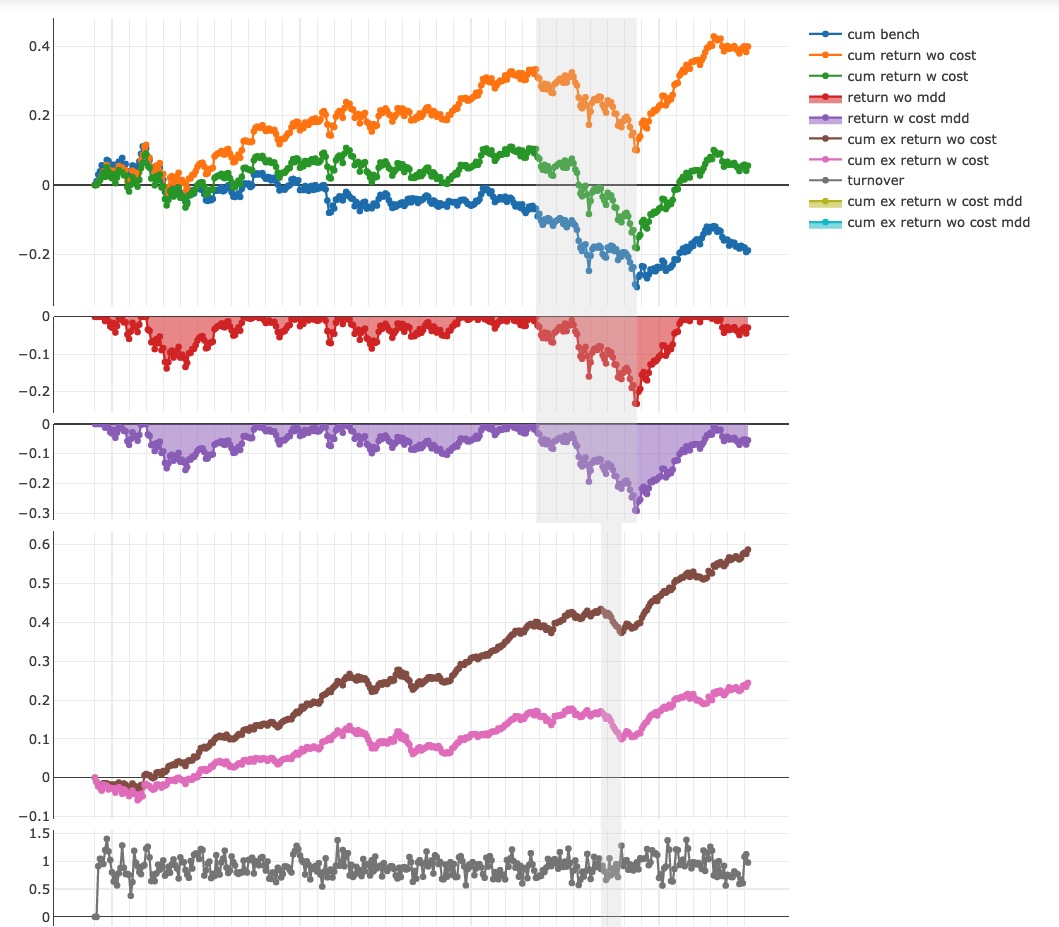
一些经过特征工程优化的模型在 2021.01.01 至 2022.08.01 在沪深 300 的股票池上可以提供 36% 的无费率年化超额,15.2% 的无换手限制扣费年化超额:
'The following are analysis results of the excess return without cost(1day).'
risk
mean 0.001539
std 0.006274
annualized_return 0.366231
information_ratio 3.783601
max_drawdown -0.061706
'The following are analysis results of the excess return with cost(1day).'
risk
mean 0.000640
std 0.006276
annualized_return 0.152256
information_ratio 1.572494
max_drawdown -0.078767
这样一来,解决了两个问题:
- Qlib 在近两年的表现如何?它仍然可以提供超额收益。
- Qlib 如何上实盘?用每日更新的数据,生成下一日的持仓,在下一日实盘进行调仓即可。
Dolt 经验
通过这个项目,我也大概对 Dolt 的属性有了一些直观的认识:
优点:
- Dolt 在版本控制方面的功能可以给数据的管理和回溯提供很多便利。
- Dolt 的 SQL 语义支持可以让数据工程师快速上手。
- Dolt 基于文件的管理方式和共享方式可以很方便地在 Linux 操作系统上部署和操作。
- DoltHub 的存在让数据的共享和协同方便了很多。
- Dolt clone,push 和 pull 提供了快捷的批量数据同步机制。想获得最新的数据,只需要 dolt pull 就可以了。
缺点:
- 在大数据量的场景下,Dolt 的性能和 SQL 数据库有几倍的差距,并且难以利用集群部署进行加速,TB 级别的数据不太适用。
- 无法自动保存执行过的 SQL 历史,对于某个 commit 来讲,可以查询到修改了哪些数值,但是没办法判断这个数值是怎么来的。
- 如果不需要全量数据的话,dolt clone 时不能只 clone 某张表。
适用场景:
- GB 级别的数据量。数据表之间强关联,大部分时候会同时使用到的。例如商品信息数据,公司信息数据。
- 修改时以手动修改为主的数据,例如监狱分布统计,博物馆藏品登记。
不适用场景:
- TB 级别的数据。
- 数据表间相关性不大,大部分下载后只用到 10% 不到的数据量。
- 数据修改主要通过脚本或 SQL 进行大批量的修改,例如用户行为统计数据。
希望这个总结也可以为后续数据项目的选型提供一些帮助。