TOC generated by https://magnetikonline.github.io/markdown-toc-generate/
相关资料
最近重新看了一下商业化的分布式存储相关的一些 paper 和资料,顺便总结一下这些系统中常用的数据结构、算法和设计上的取舍。在后续对存储系统的改造优化或者技术选型时,可以提供一些借鉴和参考。
同时在这个过程中也发现了一些面试题的影子,例如 merge k sorted list,skyline problem。同时 LSM tree 和 B+ tree 的取舍也对生活中整理事情的决策有所启发。
下面是参考过的 Paper 和资料:
- GFS - Google File System
- GFS 是 Google 在 2003 年发布的 paper,主要讲了 Google 针对内部应用开发的分布式存储系统的设计,后续被用来作为 HDFS 等系统的开发指导。主要提供的是大吞吐量的key value 存储系统。
- BigTable
- BigTable 是 Google 在 2006 年发布的 paper,主要讲了 Google 开发的结构化数据的存储系统,后续被用来作为 HBase 等系统的开发指导。
- HDFS
- HDFS 是 Hadoop 社区根据 GFS 论文中的概念实现的文件系统,是 Hadoop 生态最底层的基石。
- Windows Azure Storage
- 最初版的 Azure Storage 的设计和实现,发布于 2011年,虽然经过多年的迭代有很多细节上的变化,但是大体框架仍然延续了下来,并且支持了 Azure 当前所有的云上存储业务。
- AWS Dynamo (S3)
- AWS 的 Dynamo 发布于 2007 年,据这里说是 AWS S3 的构建基石。核心在于提供最终一致的高可用,写入“永不失败”的存储系统。
- 这篇文章中关于一致哈希的图画的很好:DynamoDB: Replication and Partitioning – Part 4
- Minio
- Minio 是一款开源的S3兼容的对象存储引擎,在2019年时,为了实现混合云的对象存储需求,调研和使用了这款对象存储引擎。并且用它对接了 S3、Aliyun OSS、Azure 等公有云。
- Minio 不像其他家的存储系统有正式的 paper,只有偏销售的介绍文档 High Performance Object Storage
- 好在 Minio 是开源的,实现细节可以在代码中自己找到:Minio
- Ceph
- Ceph 也是目前常用的储存平台,提供 S3、Swift 对象储存、 POSIX 文件储存等不同接口。
- Ceph 用到的 RADOS 存储架构
- Ceph 用到的负载分配算法 CRUSH
- Apache Ozone
- Apache Ozone 是从 Hadoop 项目中孵化出来的对象储存组件,目前已经是 Apache 顶级的项目。
- Apache OZone 除了提供单独的 Java 客户端,还提供 S3、Hadoop 兼容的接口可用于访问。
- Design Data Intensive Application
- 这本书的第三章很详细地介绍了常见的数据库以及其实现引擎的原理,也是很不错的参考资料。
持久化存储问题的剖析
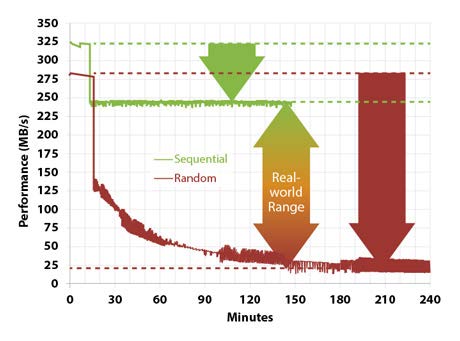
分布式存储的数据最终都是要落到每一块磁盘上的,而整体存储的性能也最终受制于磁盘的吞吐量。假设每一块磁盘的吞吐量是一个恒定值 X,那么在一个有 N 块磁盘的集群里,吞吐量就不会超过 N * X。同样的,为了把数据传输写入磁盘,需要经过网络,则整体系统的吞吐量也不会超过网络的带宽上限。所以磁盘和网络共同决定了整个系统的上限。而我们设计的目的就是让系统的性能可以尽量逼近上限。
对于目前常见的存储介质,HDD 磁盘和 SSD 固态硬盘都有一个明显的特点,就是顺序读写的吞吐量要大于随机读写。所以
- 在系统进行持久化的时候,如果能尽量进行顺序读写,就能尽可能特提高整个系统的上限。
- 对于内存来说,内存的随机读写速度比磁盘的顺序读写还要大,如果必须的顺序读写可以放在内存中来做。
- 在不得不对磁盘进行随机读写时,读出的扇页数据尽量一次包含更多后续会需要的信息,避免多次随机读写。
根据这个物理限制,可以得出常用的几种数据结构以及他们的使用场景。
常用的数据结构以及算法
首先,我们为了尽量利用磁盘的读写来增大整个系统的吞吐量,我们可以使用 SSTable 来作为磁盘存储的最小单元格式,尽量将随机读写合并成顺序读写后写入磁盘。
SSTable
 SSTable 是在 BigTable paper 中提到的用来讲数据持久化在磁盘上的最小数据单元。他将内存中的数据根据 key 排序后,序列化写入一段连续的磁盘空间内。并且把每一个 key 对应的 offset 写入到最末尾的 index 空间中。既可以多个 SSTable 可以写入一个文件,也可以一个 SSTable 写入一个文件。
SSTable 是在 BigTable paper 中提到的用来讲数据持久化在磁盘上的最小数据单元。他将内存中的数据根据 key 排序后,序列化写入一段连续的磁盘空间内。并且把每一个 key 对应的 offset 写入到最末尾的 index 空间中。既可以多个 SSTable 可以写入一个文件,也可以一个 SSTable 写入一个文件。
这样打包写入数据的方式,对比一条 key-value 数据写入一个文件的方式有几个优点:
- 可以将较少的数据合并一起写入,从而使用磁盘的顺序读写的吞吐量。例如每一对 key 和 value 仅有几十 byte,此时将数千个 key he value 打包成几十 KB 的 sstable,就可以将数千个随机读写转换为几个顺序读写。
- 在写入前进行排序,便于进行查找或者读取后在内存中构建树结构。由于数据经过排序之后才写入,如果需要将其读取出来,在内存中构建平衡二叉树例如 AVL 树或者红黑树,则速度会更快。同时如果要查找某一个key值,加载包末尾的 index 空间即可。
- key-value 的形式可以很容易地支持其他上层应用。例如 key-value 可以储存 map,如果 key 为 index 则可以用作储存列表,而 value 本身也可以储存任意可以序列化的数据结构。
但这个方式也有缺点:
- 被打包的数据只能一起读写 如果需要加载或者写入某一条数据,不能单独进行更改,只能跟其他数据一起合并等待写入。
由于这个缺点的存在,使用 sstable 的储存系统,往往都会在内存中有缓存,从而将需要进行修改的数据一起打包合并之后再进行写入。这也是 LSM tree 的设计理念之一。
Write ahead log
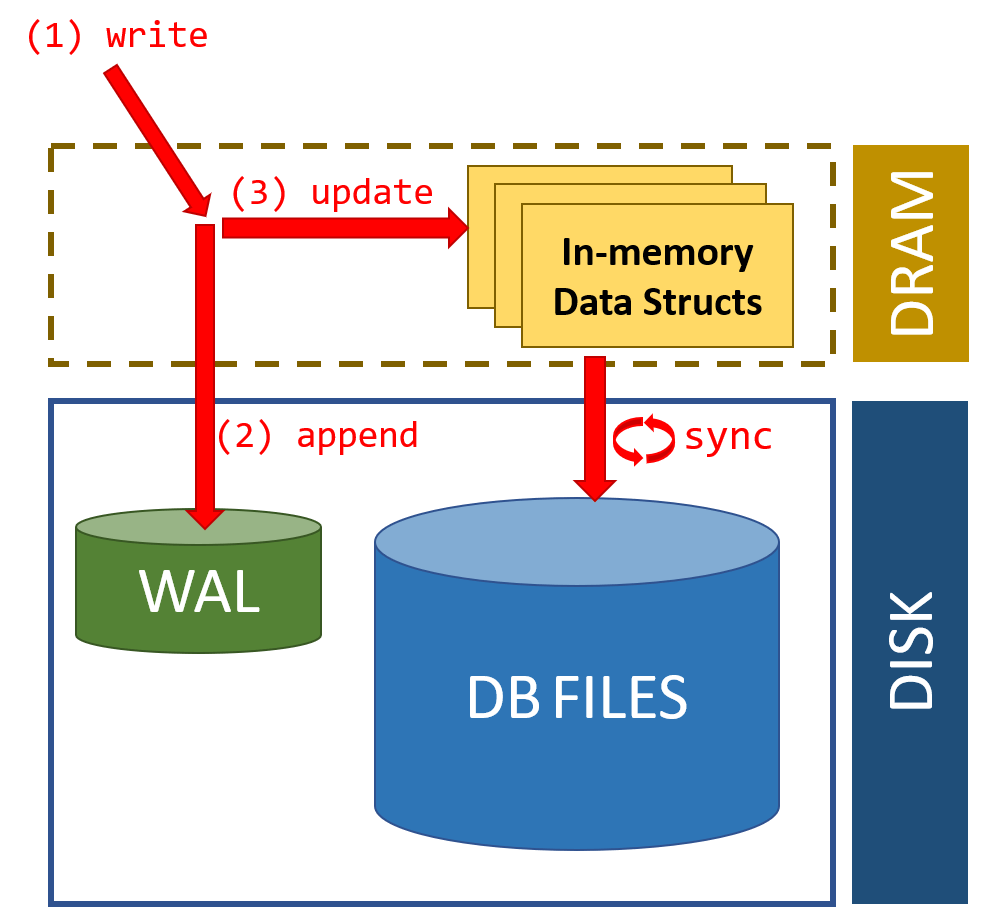
由于 SSTable 只能将多条数据同时进行读写,那么对某一条数据的写入就不能实时生效,这时候怎么实现系统的实时性呢?很容易想到的是用 WAL (Write ahead log) 来保证。
Write ahead log 记录的是所有对存储系统进行修改的操作,一旦操作写入了 write ahead log 后,如果系统崩溃或者重启,就可以通过 write ahead log 进行回放来重新构造系统应该处在的状态,例如增加一条数据,删除一条数据等等。结合 sstable 的使用,当新增的数据操作进入系统后,先写入 write ahead log,然后缓存这条数据在内存里,就可以返回成功了,后续等内存中的数据足够多后,打包成一个 sstable 写入磁盘即可。
WAL 的难点主要在如何提高处理高并发情况下的写入。例如使用单个 WAL 的话,如果有一个大的请求需要写入 50MB 的数据,这时候其他 1KB 的数据可能就需要等待这 50MB 写入完成后才能继续。此时多个写入请求可能就会导致整体请求速度变慢。
如此一来,我们 write ahead log 和 sstable 都是顺序写入,同时还利用了内存的高速随机读写,获得了高速的数据写入的速度和吞吐量。但是仍然有3个问题没有解决:
- 如果我们要修改一个数据怎么办?
- 如果我们要读取一个数据怎么办?
- 如果我们要删除一个数据怎么办?
LSM tree
LSM 树是一种分层的数据结构,用来解决上述的 3 个问题。

为了能修改一个数据,LSM tree 对每个 SSTable 增加一个层级的概念。即先写入磁盘的 sstable 是比较老的,后写入的 sstable 是比较新的,在内存里的是最新的。例如第一层的 sstable ID 是 1-
假如不同的 sstable 都包含同一个 key 值,则最新的 sstable 中包含的 key 对应的 value 是最新的。这样一来,如果我们需要修改一个数据,只需要在系统中添加一条新的数据就可以了,在这个分层的定义中,新的数据会使得旧的数据失效。这意味着修改和写入的复杂度都是 O(1)。
那么如何读取一个数据呢?由于 sstable 是分层的,所以最简单的方法就是从新到旧遍历所有 sstable,直到找到第一个包含这个 key 值的 sstable,并读取它的 value。如果没有找到对应的 key,则表示 key 不在系统中。这意味着读取的时间复杂度是 O(N),N 是需要访问的 sstable 的数量。
【面试题插入】假如 key 值是 a:int -> b:int 这样一个数字段,那么这个查询的过程其实就是面试题中的 skyline problem。
- skyline 中的 building 对应的就是不同层级的 sstable
- 每个 building 的 height 对应的就是每个 sstable 的层级
- building 的 left 和 right 对应的就是 sstable 中 key 的范围
- 而 skyline 代表的,就是每个 key 对应的 range 应该去访问哪个 sstable。
- 这个问题的目的,转化到存储系统中,就是在给定一个 key 时,可以快速找到对应 sstable 的映射关系。 利用这样的 key 形式,我们就可以支持对一个 key 是数字范围的写入和读取了,这对于实现一个虚拟磁盘是有帮助的。这个问题也是Multiple Object Optimization 的一类。
那么如何删除一个数据呢?由于 sstable 是分层的,只要在系统中添加一条新的数据,把某个 key 值标记为已被删除,后续读取的时候,读取到这个删除标记,就知道这个 key 已经被删除了。这意味着删除的复杂度也是 O(1)。
Memtable
LSM 在处理写操作时,会先把数据存在内存中,所以内存中的数据也可以看作是整个系统最上层的缓存,LSM 把内存中的这部分数据叫做 memtable。Memtable 一般使用平衡二叉树例如 AVL 树或者红黑树进行储存,从而提供 log(N) 的稳定存取速度。之所以没有使用哈希表,是因为 memtable 在增长到一定程度时,需要将 key value 排序转换成 sstable 写入磁盘,使用哈希表不利于排序的进行。
每次当 memtable 写入磁盘后,Write ahead log 就可以删除原来的 log 文件,新建一个新的 log 文件。或者也可以标记 log 文件的某个 offset 为已持久化的 checkpoint。这样一来如果遇到宕机,只需要重放 checkpoint 之后的操作就可以了。
Compaction

而由于 sstable 的数量会随着系统的使用不断变多,层级也会不断变多,所以就有了 compaction 的概念。当 sstable 的大小、数量或者层级达到一定阈值时,会触发类似 GC 的异步批处理任务,将多个小 sstable 合并成一个大的 sstable,或者将新的 sstable 合并入老的 sstable 中。这个 compaction 的过程利用了 sstable 是一个排序后的链式储存的特点,可以利用类似 merge sort 的方法使用顺序读写将多个 sstable 合并成一个。
【面试题插入】这个合并 sstable 的过程,其实就是面试中常问到的 merge k sorted list 问题。
Compaction 的过程完成了 LSM 对数据的增、删、改、查的最后一环,数据的删除只会在 compaction 的过程中发生,从而其他所有的操作都简化了。但是也有几个问题:
- 当 sstable 数量比较大时,为了查询某个 key 值是否存在在 sstable 中,会需要读取多次 sstable 的 index block,会导致多次的随机读写。
- 对系统的一条数据进行修改时,可能发生了多次写操作,例如 memtable 转为 sstable 发生了一次,后续每一次 compaction 又是一次,有写放大的问题。
Bloom filter
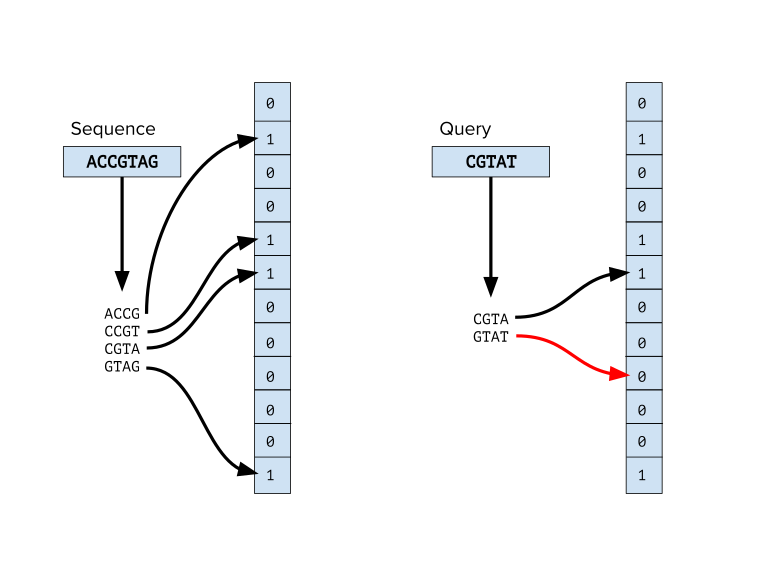
为了解决当 sstable 数量大时,每次查询一个 key 是否存在,需要对多个 sstable 的 index block 进行随机读写的问题,可以使用 Bloom filter 在内存中缓存 sstable 和对应的 bloom filter 进行优化。
Bloom filter 本质上是利用哈希算法生成数据的特征值,后续通过对特征值的比对,确认元素是否存在,它的目的是过滤掉元素不存在的那些 sstable,从而大大减少随机读写的频率。而 Bloom filter 也可以想象成是不处理哈希碰撞、哈希空间很小、且不保存值的哈希表,利用哈希碰撞概率不高的特点,高效地在内存中存储元素的特征点。
通过 bloom filter,可以大大减少读取时 O(N) 的 N 值。
Prefix Bloom filter
Bloom filter 一定程度上解决了 LSM 树的读放大问题,但是它只解决了随机读写时,输入完整 key 值的读放大问题。假如需求是读取 ID 从 [1200 - 1800] 范围的数据,Bloom filter 就不能直接提供帮助了。
这时候 Prefix Bloom Filter 就可以进一步提供帮助,用 key 值的前缀生成 bloom filter,可以用来判断当前搜索的范围是否在这个 sstable 中存在。
由此可以看到 LSM 树的特点:
- 写入、修改、删除操作都是 O(1) 的复杂度,读取是 O(N) 的复杂度,所以对于写入操作居多的时候有很好的性能,但是对于读取的 IO 数量支持有一定劣势。
- 对于写入数据的内容不进行解析,也就不能做事务性的操作,也不好做联合查询等复杂的操作。
- 在进行顺序扫描时,需要读取大量 sstable 进行合并,也会有读放大的问题。放大倍数是 log(n),n 是 LSM 的层数
- 在进行 compaction 的时候,对于资源有比较大的占用,有可能会因此导致写入或者读取性能的降低。
- 不易产生磁盘碎片
B+ tree
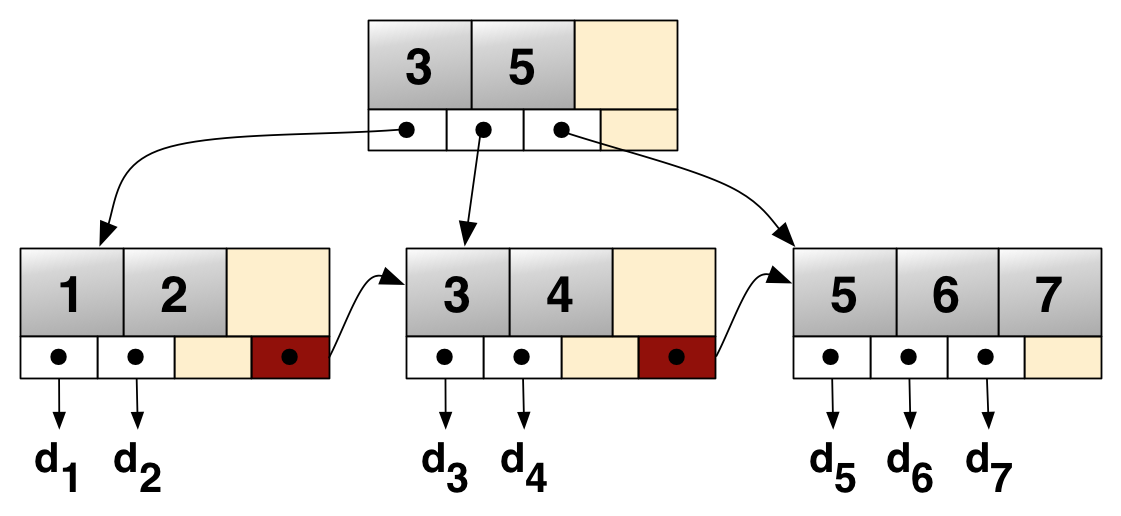
B 树和 B+ 树都是经典的数据存储结构。B 树相对于二叉树的主要区别就是每个节点下面的子节点的个数较多,二叉树只会有2个子节点,但是B树可以有几十个到几千个。
而 B+ 树则是针对需要在磁盘上持久化,而在 B 树的基础上做的优化。,将所有的数据都放在叶子节点,中间节点只储存下层节点的信息,从而使得整个树的层数更少。由于每一层的查找都是磁盘的一次随机读操作,所以层数少也使得随机读的次数更少。
B+ 树在读取时比较简单,只需要根据树的信息找到对应节点并返回即可。但是在写入的时候,B+ 树需要进行节点的分裂和更新,可能会产生大量的随机写,同时由于数据的更新是在磁盘中的 in place write,所以随机写较多,无法利用磁盘的顺序写的性能。
那么为什么 B+ 树仍然作为不少关系型数据库的储存引擎呢?用 B+ 数作为存储引擎也有不少好处:
- 整体结构更简单,内存中的结构和磁盘上的结构区别不大。
- 查询速度更快更稳定。对于读操作较多的应用来说,优化读操作的 IO 延迟和吞吐量比优化写入吞吐量更重要。
- 更容易进行数据的顺序扫描,数据的叶子节点上都包含指向下一个数据点的指针。
系统内有序性的取舍
B 树和 LSM 树本质上反映了对系统中如何保证有序性的取舍:
- B 树代表的是每一次操作前后都保证系统内的有序结构,即 key 值永远是以树形式排序储存的。
- SSTable + LSM 树代表的是允许局部无序,从而将随机读写转换为顺序读写,并在后续的异步 compaction 任务中重新整理,并且构建。
整体系统内为了维护有序性,要要做的工作其实没有减少,取舍的是放在什么时候做。
同样的,我们也可以用平时的整理房间、整理桌面来思考这个场景:
- B树相当于一个非常自律的人,所有的物品都分门别类规划好放置的地方,每次用完或者购买新的东西,都会放到它该放的地方。如果买了一支笔,但是笔筒满了,他也会再买个更大的笔筒,来保证桌面的整齐。这样一来他平时花在整理房间的时间会比较多,但是要找东西的时候就会比较快。
- LSM 树相当于一个不拘小节的人,平时用完东西或者买了东西就随手一放,但是桌面太乱或者一段时间没整理的话,他也会把所有物品拿出来分门别类重新放好,免得自己找东西太麻烦。这样一来他平时不需要花时间整理房间,但是需要每一段时间专门空出精力整理。
分布式背景下的系统设计
前面的存储技术主要针对的是单机场景下的存储,在单机场景下提供储存功能的组件,一般也是我们常说的数据库引擎,例如 RocksDB、LevelDB 等。它们提供了几乎每个数据库都需要解决的基础问题,即 ACID 中的 A (Atomicity) 和 D (Durability)。
在分布式的情况下,就需要多解决几个问题:
- 分片问题:写入磁盘的时候,是写入哪一块磁盘?
- 数据恢复:当某一台节点挂了,怎么恢复这个节点上的数据?
- 节点在线状态的同步:如何知道哪些节点是可用或者不可用的
这里有两个解决的思路:
- 一个是使用主从结构,在 master 上记录每条数据存入的磁盘以及 slave 的 host name,而所有的磁盘挂载在 slave 下。
- 另一个则是使用哈希来进行负载的分配,通过对储存的 ID 哈希后分发到对应的磁盘和机器上进行查询、处理或储存。
主从结构

在主从架构中,master 主要储存的是元信息,包括:
- 有哪些 slave 目前还可以正常运转,每个 slave 的 CPU、内存、磁盘使用情况等信息。
- 每个数据块对应存储在哪个 slave 上
当有新数据需要存储时,可能需要 master 将这个数据块注册到元信息中。这类数据块往往不会是小文件,否则小文件多的话,元信息会太大,无法在一个 master 节点上存下。
同时,由于 master 操控了所有 slave 的负载分配,也可以做出不少负载均衡上的优化,例如:
- 当某个 slave 的存储空间快满了,可以减少它存储的新数据,同时迁移一部分旧数据到其他节点
- 当某个 slave 上出现热点数据时,可以增加热点数据的备份,使得多个 slave 可以同时 serve 一份数据。
主从结构是许多系统采用的,他本身有许多好处:
- 架构清晰明了,元信息的处理都在 master 上发生,数据存储都在 slave 上发生。
- 可以提供更细致的负载均衡,当发生宕机时,可以更灵活地从其他 slave 节点进行恢复或者调度。
- 可以在 master 机上小范围内解决拜占庭将军问题,大部分的组件不需要关心共识问题。通过与 Master 节点的通信来决定哪些 slave 节点是可用的。
但是主从结构也有部分缺陷:
- master 是集群中可能出现单点故障的部分,所以往往对 master 也需要有额外的主备结构进行冗余的保护,或者 master 本身也需要是一个集群。这就导致部署会比较复杂,需要对 Master 进行一次配置、初始化,同时对 Client 也需要做一遍配置,而且两部分的配置时相互依赖的。同时为了保证 Master 的高可用,需要有额外资源来保证冗余,例如 Master 需要 16核 128G 的机器,那么就需要预留2-3台同样大小的资源来预防宕机。
- 读写数据时需要先向 master 请求元信息,可能会增加读写数据时的延迟和资源开销,同时也可能会成为整个系统的性能瓶颈。这一点往往需要客户端使用缓存来进行优化。
哈希分配
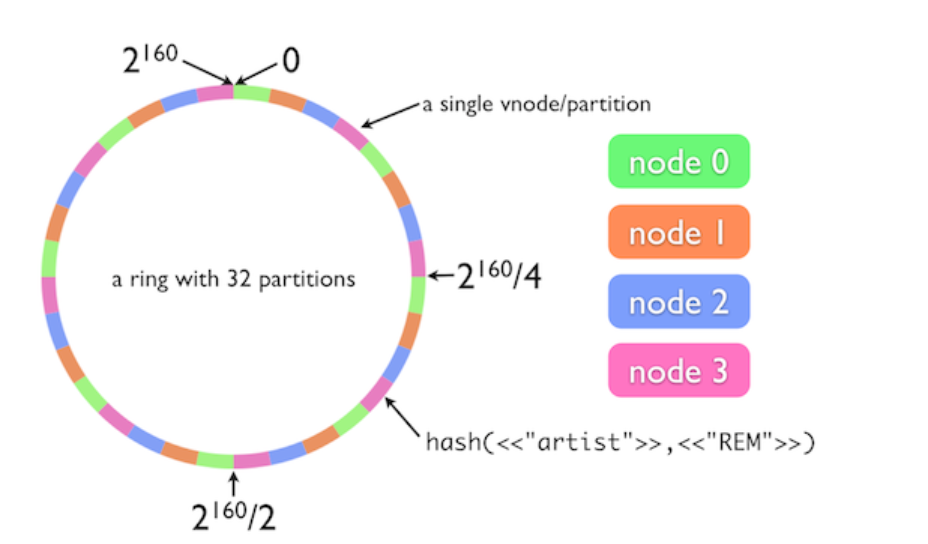
使用哈希进行负载分配,就是当一个写数据的请求进入系统时,根据请求的某些特征,例如数据的 key 值进行哈希。使用数据的哈希值除余节点数后,用余数的值决定应该分配到哪台机器的哪个磁盘上进行储存。这个方法使得集群中所有机器的地位相同,任意一台机器都可以进行哈希计算,也就没有了主从结构中单点故障的风险。同理,我们也可以用伪随机的算法实现同样的效果
使用哈希分配负载时,主要的问题在于扩容、缩容和故障恢复时的处理,当集群中的机器数量发生变化时,往往会对哈希值产生影响。例如原本 key 为 “abc” 的数据映射到 x 和 y 机器上,当数量变化后,可能就映射到了 m 和 n 机器上了。目前看来有2种方法来处理:
- 使用一致性哈希 + 数据迁移的方法。一致性哈希算法保证了当哈希表的大小变化后,需要变化的值的数量只有 n/m 个,n 是系统中所有 key 的数量,m 是哈希表上节点的数量,即把需要迁移的 key 数量降到最低,从而减少系统迁移数据的负载。使用一致性哈希时往往也会使用虚拟节点。即一个物理节点映射到多个哈希空间中的虚拟节点,从而使得节点添加和移除时,负载可以均匀地被分配到多个其他虚拟节点上,而不会导致单个相邻节点的负载激增。
- 不支持对集群的扩容和缩容,但支持新加入的节点组成新的集群,同时做跨集群的负载均衡。就是说在集群内如果有少量机器挂了,不影响集群内的读写操作。如果容量满了,则可以触发跨集群的负载均衡,将新写入的数据转发至其他集群进行处理。
哈希分配的方式在负载均衡上有两种选择:
- 使用一个普通的负载均衡器将请求分发到一个不繁忙的机器上,然后由这台机器进行转发或者处理。这样对客户端的要求更简单更轻量。
- 用一个特殊的客户端,客户端中可以提前储存或者计算某个key应该被哪个机器处理,然后直接发到这个机器上,这样可以实现更低的延迟。
哈希分配在部署运维时有不少好处:
- 在部署和运维时,所有机器都是一视同仁的,不需要针对某些机器进行特殊的配置和管理。代码、配置、脚本都会简单很多。
- 在写入和查询时,不需要访问元信息表,节省了访问和维护元信息表的开销和延迟,元数据的管理分散到了所有参与集群的机器上。
- 使用哈希分配的系统由于没有 master 的存在,可以容忍的同时宕机的机器数量也会更多,理论上可靠性会更好。
- 使用哈希分配没有单点,所以在预防宕机时,不需要为 Master 类型的部署单独准备冗余机器。
但同时也有不少挑战:
- 代码内部的架构相对复杂,所有元信息的同步需要在每一台机器上进行收集和处理,并且需要整体处理拜占庭将军问题。
- 负载均衡依赖于哈希算法本身的优越性,难以在部署后对负载进行灵活调整。
- 热点数据难以扩展
其他分布式系统用到的技术
有一些技术并没有明确的兼容性或者优越性,即在大部分系统上可以用也可以不用,用了之后只是对不同场景提供一个取舍的选项。下面也简单整理了一下:
Erasue Coding 纠错码
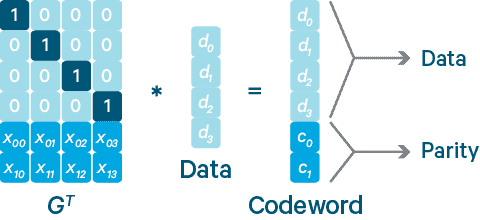
原理:
纠错码可以理解成提供2个接口:
- 编码:输入是 (原始数据 data,数据块数 n,冗余块数 k),输出是 [数据块 * n, 冗余数据块 * k]
- 解码:输入是 (n+k) 个数据块或冗余块,输出是原始数据。
这就意味着纠错码在分布式储存系统中,可以通过使用更少的空间,提供相同程度的冗余。例如 8+4 的纠错码配置,8 为 datablock 的长度,4 为纠错的 parity block 长度,则可以提供 4 份冗余空间,使用的空间是 1.5 倍原始数据大小。相比之下如果在12个磁盘的集群上,相同程度的冗余就需要5份完整复制的数据才能达到,使用空间是 5 倍原始数据大小。
使用纠错码时,如果所有的 datablock 都可读,则读取时只需要简单把 datablock 拼接在一起即可。因为单位矩阵的逆矩阵还是单位矩阵。但如果某些 datablock 不可读,则需要求逆矩阵后进行计算,会有一定的额外计算开销。
所以纠错码的缺点在于:如果通过纠错码恢复,则读取时需要使用 CPU 进行矩阵求逆的计算。相当于用 CPU 资源换取磁盘资源。目前高效的 Reed Solomon 纠错码计算可以达到 1GB/cpu core/second,至于是否要使用主要看成本的取舍了。
压缩加密
如果储存系统是针对某类应用的话,比较适合提供压缩和加密功能。例如 BigTable 使用的 Bentley and McIlroy’s 据说对 Google 内部应用能达到 10:1 的压缩率,就是由于储存的很多数据都是 html 的网页数据。但是部分应用系统比如 Google Earth 就选择不使用压缩功能,因为在应用层已经压缩过了,再次压缩的话压缩率不高。
使用压缩算法其实也是用 CPU 换储存空间的一种做法,是否使用主要看压缩率能达到多少。
Quorum
在分布式储存系统中,为了保证数据冗余,往往会写入多个备份。而 Quorum 在这里一般有3个参数:
- N 总备份数量
- W 写入时需要至少要成功的写备份数
- R 读取时需要至少要成功的读备份数
当 W+R > N 时,才能保证数据的最终一致性。例如常见的 WARO (Write All Read one) 模式,N=3,W=3,R=1,则表示只有当写入所有备份都成功后才返回成功,而读取时只需要读取一个备份即可返回。
此时为了优化性能且不牺牲一致性,往往会把 W 和 R 设置得尽量小,但仍满足 W + R > N。这个在部分储存系统中时可以调节的系统参数。比如在 AWS Dynamo 中就有服务设置 N=3, W=1, R=3
PS. 部分系统声称的高可用,其实是牺牲了写入高可用从而给读取提供高可用。CAP 理论中的 C、A、P 可以拆开在不同层级的不同操作上适用,牺牲写入高可用换取读取高可用也是常见的配置。
客户端的服务发现
无论是主从架构还是哈希分配的架构,对于一个简单的 HTTP 客户端,往往需要先从 Master 获取自己想要数据对应储存的主机地址,或者由目标集群中的机器通过哈希算法进行转发。这就导致请求的延迟由两部分组成:
- 元信息获取延迟
- 主从结构:从 Master 机器获取储存节点的延迟
- 哈希结构:由集群机器转发至对应储存节点的延迟
- 请求实际处理的耗时
如果要实现更低的延迟,可以使用在客户端进行的服务发现和负载均衡:
- 主从结构:
- 在客户端缓存自己所需数据的储存节点信息,后续请求可以不需要向 Master 进行请求。
- 提前从 Master 获取完整的储存节点映射表,并缓存在本地,后续只要定期从 Master 获取最新的映射表即可。
- 哈希结构
- 客户端使用和服务端相同的哈希算法,计算每个数据对应储存的节点应该是哪个,发请求时直接根据哈希结果进行发送。
使用客户端的服务发现和负载均衡时,可以减少至少一跳的网络传输,优化整体端到端的延迟。
但是主要问题有:
- 更新节点映射表时可能导致网络风暴。当储存节点信息发生变化时,大量客户端同时请求更新,如果有 1000 个客户端,每个客户端更新 10M 数据,则需要传输 10G 的数据,从而变相发起了 DDOS 攻击。
- 客户端臃肿。由于客户端的逻辑变复杂,会导致客户端占用的 CPU 和内存资源增加,在部分 IoT 设备或者低功耗设备上不适用。
- 更新难度大。由于客户端逻辑和服务端架构强绑定,在更新相关接口时,需要保证反向兼容,或者要保证同时更新客户端,对代码升级部署有一定难度。
不同系统的实现取舍
许多系统在实现时,并不是单一互斥的选型,在不同层级或者不同组件中,可能会混用前面提到的数据结构和算法。例如 GFS 在内存中用 B+ 树来管理元信息,用 LSM 树来管理实际储存的大数据块。
下面简单对比一下不同系统使用的主要技术和使用场景:
整体对比

在功能和提供的接口上,大致可以分为两类:
- 只提供大文件的储存:
- GFS
- Windows Azure Storage Stream
- HDFS
对于大文件的储存基本都是使用不可更改的数据包作为磁盘储存,并用主从结构分配储存负载。
- 提供 key value 或 key columns 储存:
- BigTable (LSM Tree + 主从结构)
- Windows Azure Storage (LSM Tree + 主从结构)
- AWS Dynamo (B+ Tree + 哈希分配)
- Apache Ozone (LSM tree + 主从结构 + 单个分片服务)
- Ceph (LSM tree + 哈希分配)
- Minio (Linux 文件系统树 + 运行时遍历)
GFS

- 设计目标:
- 为大数据量(GB级)顺序读写的性能而优化,牺牲随机读写的性能
- 对外提供的接口:
- 类文件的 key value 储存
- 磁盘储存方案:
- 在磁盘上保存 64MB 大小的 chunk,多个 chunk 共同组合成一个逻辑上的“文件”。Chunk 是磁盘储存的最小单元。
- 已写入的 Chunk 不可更改,如果要修改需要重写一个新的 Chunk
- 分布式模型:
- 主从结构:Slave 也叫 Chunk Server
- 元信息管理方案:
- Master 管理:
- 系统中保存的文件列表 (树结构)
- 每个文件包含的 Chunk ID 列表
- 每个 Chunk 存放在哪个 Chunkserver 上
- 初始化时由 Slave 上报给 Master 已保存的 chunk ID
- Master 管理:
- 其他技术使用
- Master 使用 WAL 保证可靠性,同时在内存中缓存 Metadata 的信息,定期写入磁盘,从而提高吞吐量。
- 未提及 Erasure Coding 的使用,直接复制完整数据提供冗余。
- 使用类似 LSM tree 中的 Compaction 进行数据整理和更新,例如删除已失效的 chunk。
- 设计取舍
- 由于 Google 应用的数据量大,所以必须使用 MapReduce 一类的分布式并行计算方案做处理,从而也使得传统 SQL 数据库的单机事务处理并不适用,也就不需要储存系统有计算功能,所以 GFS 只需要做好 “储存” 这一件事即可。在此基础上,根据使用场景主要是大数据量的 MapReduce,GFS 很明确地舍弃了随机读写的性能,并着重优化大数量级的顺序读写。
- 由于只需要做好大文件的储存功能,使用主从结构可以大大减少整体复杂度。Master 只需要处理元数据,而 Slave 只需要做好数据储存即可。
- 为了实现高吞吐量的磁盘读写,以较大的 Chunk 作为储存单元,也就要求使用的应用需要自己将多条小数据打包成一个大数据包 (GB级),例如将多个 html 网页打包起来,或者将 bigtable 中的多条 row 打包起来作为一个文件存储。
BigTable

- 设计目标:
- 提供超大规模的非关系型结构化数据储存
- 对外提供的接口:
- 类似 Sorted Map
- 磁盘储存方案:
- 将 sorted map 以 sstable 的形式存入 GFS 中
- 分布式模型:
- 主从结构:Slave 也叫 tablet server
- 元信息管理方案:
- Master 进行创建、更新、删除:
- 系统中保存的 table 列表(树结构)
- Table 中保存的分片(tablet)对应存在哪些 tablet server 上
- Master 中的信息持久化在 Google 的另一个服务 Chubby 上
- Master 进行创建、更新、删除:
- 其他技术使用
- 利用 WAL 保证可靠性,同时在内存中使用红黑树或者其他平衡树临时储存尚未写入 GFS 的数据
- 使用类似 LSM tree 中的 Compaction 进行 sstable 的整理和更新
- 设计取舍
- 与 GFS 类似,由于 Google 应用的数据量大,所以必须使用 MapReduce 一类的分布式并行计算方案做处理,从而也使得传统 SQL 数据库的单机事务处理并不适用,也就不需要储存系统有计算功能,所以 BigTable 只需要做好 “储存” 和 “结构化” 即可。
- BigTable 提供的主要是结构化的数据抽象,由于底层使用的是 GFS 这样的大文件储存系统,所以在进行存储时需要尽量进行大块的顺序读写,所以选择的是 LSM tree 而不是 B+ tree
- BigTable 并未牺牲随机读写的性能,所以比 GFS 稍微复杂的一点就是 data path 上会用内存对数据进行缓存,同时利用 WAL 保证可靠性。这也是牺牲了在宕机后恢复状态的速度,从而换取大多数时间下的更低的读写延迟。
HDFS

HDFS 的架构和 GFS 很像,可以将名词一一对应减少理解难度:
| HDFS. | GFS |
|---|---|
| A Block | A Chunk |
| Edit Log | Operation Log |
| Data Node | ChunkServer |
| Name Node | GFS Master |
- 设计目标:
- 为大数据量(GB级)顺序读写的性能而优化,牺牲随机读写的性能
- 对外提供的接口:
- 类文件的 key value 储存
- 磁盘储存方案:
- 在磁盘上保存 128MB 大小的 Block,一个 Block 是一个文件。Block 是磁盘储存的最小单元。
- 由 Data Node 控制文件夹结构,避免一个文件夹中的文件数量过多
- 分布式模型:
- 主从结构:Slave 也叫 Data Node
- 元信息管理方案:
- Master 管理:
- 系统中保存的文件列表 (树结构)
- 每个文件包含的 Block ID 列表
- 每个 Block 存放在哪几个 Data Node 上
- 初始化时由 Data Node 上报给 Name Node 已保存的 Block ID
- Master 管理:
- 其他技术使用
- Name Node 使用 Edit Log 保证可靠性,同时在内存中缓存 Metadata 的信息,定期写入磁盘,从而提高吞吐量。
- 未提及 Erasure Coding 的使用,直接复制完整数据提供冗余。
- 使用类似 LSM tree 中的 Compaction 进行数据整理和更新,例如删除已失效的 Block
- 设计取舍
- 基本上是照着 GFS 做的,所以项目的前提条件也相同,他们都是为了大文件设计的,所以对于大量的小文件处理并不理想。当小文件多的时候,元数据占用的空间会逐渐增加,导致 Name Node 成为系统的瓶颈。下面会聊到的 Apache Ozone 就优化解决了这个问题。
Azure Storage
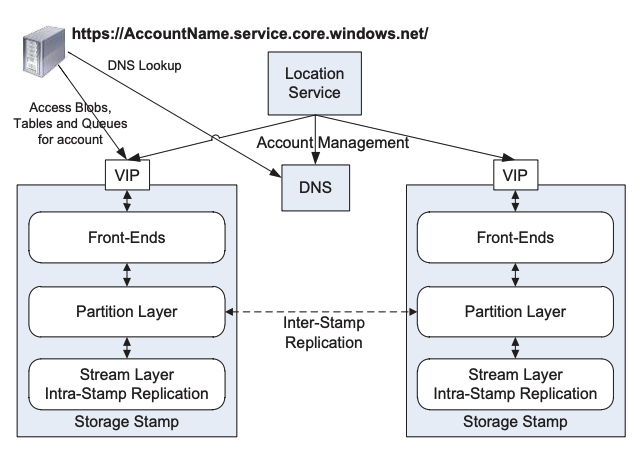
Azure Storage 的架构和 GFS + Bitable 很像,可以将名词一一对应减少理解难度:
| Azure Storage | GFS | Bigtable |
|---|---|---|
| Stream Layer | GFS | |
| A Stream | A File in GFS | |
| An Extent | A Chunk | |
| Journal Drive | Operation Log | |
| Lock Service | Chubby | Chubby |
| Partition | Tablet | |
| Partition Server | Tablet Server | |
| Checkpoint | SSTable | |
| Memory Table | Memtable | |
| Garbage Collection | Compaction |
Stream 层
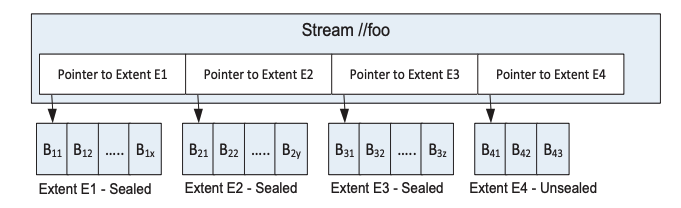
- 设计目标:
- 为 Partition 层提供可靠的储存接口,提供 CAP 中的 A 和 P,其中 C 部分需要使用者额外处理。
- 对外提供的接口:
- 类文件的 key value 储存
- 操作类型:create / delete / open / close / read / append / rename
- 磁盘储存方案:
- 由 Stream 层提供,在磁盘上保存多个 Block (Eg. 4MB),每个 Block 都不可修改。Block 是磁盘储存的最小单元。
- 每次写入都会生成若干个 Block,多个 Block 组成 Extent,多个 Extent 组成 Stream。
- 每个 Extend 是磁盘上的一个文件。
- 分布式模型:
- 主从结构:Master 叫 Stream Manager (SM),Slave 叫 Entent Node (EN)
- 元信息管理方案:
- Master 处理:Stream - Extend 的关联元信息:
- 系统中保存的 stream 有哪些
- 每个 Steam 包含的 Extend ID 列表
- 每个 Extend 存放在哪个 Extend Node 上
- Slave 处理:Extend - Block 的关联元信息:
- 每个 Extend 由哪些 Block 组成
- Master 处理:Stream - Extend 的关联元信息:
- 其他技术使用
- Master 使用 WAL 保证可靠性,同时在内存中缓存 Metadata 的信息,定期写入磁盘,从而提高吞吐量。
- 支持 Erasure Coding
- 使用类似 LSM tree 中的 Compaction 对 EN 中不被引用的 Block 进行数据整理和更新
- 设计取舍
- Azure 的 Stream 层使用 Immutable Append Only 的储存层,有个明显的好处是更容易进行 snapshot 操作。Snapshot 对于云服务的用户来讲是个常用的功能,由于 Extend 是不可修改的,所以只需要增加几个对 Extend 的 reference 就能完成 stream 的 snapshot 操作,代价低并且速度快。
Partition 和 FE 层
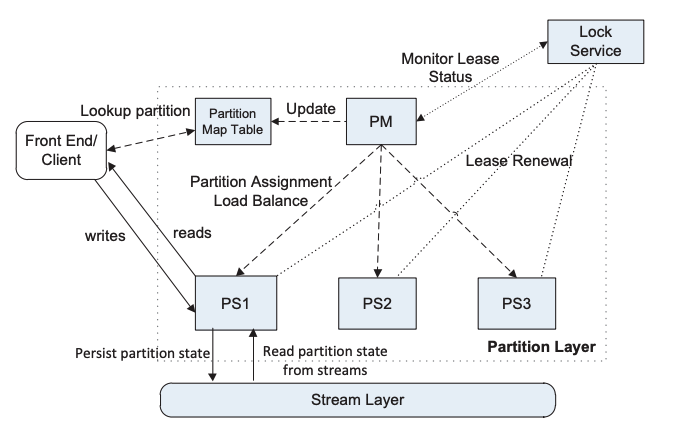

- 设计目标:
- 提供大规模云上的Blob、Table 和 Queue 的储存服务
- 对外提供的接口:
- Key Value Blob Object: create/delete/get/put
- Table
- 磁盘储存方案:
- 将数据写入 stream 中并记下 stream 的 offset,文件 = stream id + offset + length
- 类似 LSM tree 的分层方式将数据写入 stream 中
- 分布式模型:
- 主从结构:Master 叫 Partition Master (PM),Slave 叫 Partition Server (PS)
- 元信息管理方案:
- 由 Partition Manager 进行 partition 的创建、修改、分割、合并、分配等操作:
- 系统中保存的 table 以及 partition 列表(树结构)
- 每个 partition 与 partition server 的对应关系
- 由 Slave 对 partition 内的元信息作更新:
- parition 包含的 commit log stream、row data stream 等
- 由 Partition Manager 进行 partition 的创建、修改、分割、合并、分配等操作:
- 其他技术使用
- 利用 WAL 保证可靠性,同时在内存中使用红黑树或者其他平衡树临时储存数据
- 使用类似 LSM tree 中的 Compaction 对 Partition 中过大的 Checkpoint 进行合并,重写进新的 stream
- 设计取舍
- Azure 和 GFS 主要的设计区别来自于它需要服务的更多是云上的客户,而不仅仅是内部客户,所以对于负载的分布和使用模式没有掌控。
- 使用 Range Partition,也就是将大的表根据主键拆分分片,而不使用哈希分片的原因。
- 是因为云服务是个多租户系统,需要对每个用户进行限流和管控,避免 noisy neighbor 的影响。使用 Range Partition 可以更容易通过主键设计把同一个用户放在一个 Parition 上,从而形成对租户的隔离。
- 另一个是可以进行更细粒度的负载均衡,哈希分片依赖于请求的哈希值分配不会有过大的 skew,但在云服务的场景下,这个并不能被保证,因为云服务需要接纳各种使用场景,例如某位明星的微博可能导致瞬时流量激增,对于哈希分片就无法做负载调整,但是对于 Range Parition 就可以进一步做 Range Split 从而提高性能。
- Paper 中提到 Azure 可以同时提供 CAP,但其实本质上是牺牲了写入的高可用 A 来提供读取的高可用 A,并不是在全场景下的 CAP。
Apache Ozone
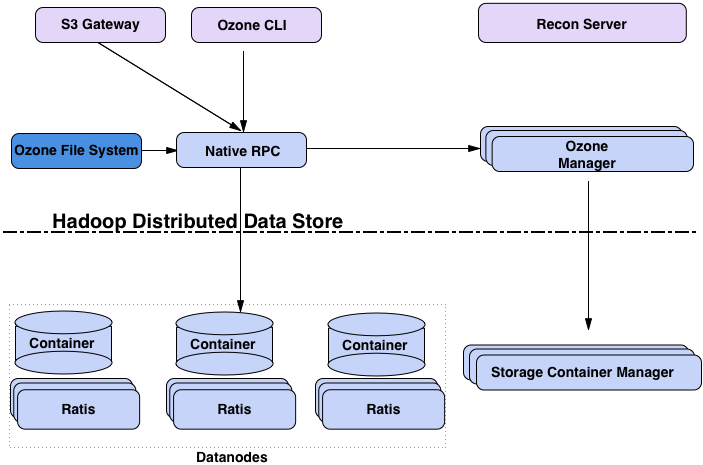
Apache Ozone 的架构和 GFS 比较像,可以将名词一一对应减少理解难度:
| Apache Ozone | GFS |
|---|---|
| Hadoop Distributed Data Store | GFS |
| A Container | A File in GFS |
| A Block | A Chunk |
| Ratis Log | Operation Log |
| Raft protocol | Chubby |
Apache Ozone 和 GFS 相比主要的区别在于增加了一层 Ozone Manager,将底层的大文件储存转换为了类似对象储存的接口。
- 设计目标:
- 提供可扩展、高可用的对象储存。
- 对外提供的接口:
- Key Value Blob Object: create/delete/get/put
- 磁盘储存方案:
- 由 HDDS (Hadoop Distributed Data Store) 提供,HDDS 由 Storage Container Manager (SCM) + Data Node 组成。
- Data Node 在磁盘上保存多个文件,同时用一个 Rocks DB 保存元信息。
- SCM 使用 Rocks DB 在本地保存元信息。
- 分布式模型:
- 主从结构:Master 叫 Storage Container Manager (SCM),Slave 叫 Data Node
- 元信息管理方案:
- 独立的 Ozone Manager 处理:
- Object Key -> (Container ID + Local ID) list 的映射
- Auth、ACL、Quota 等信息
- Master (SCM) 处理:
- Container ID 由哪些 Data Node 提供服务的映射
- Container ID + Local ID -> Block ID 的映射
- Data Node 处理
- 每个 Container 由哪些文件组成
- 每个 Container 里的 Local ID -> (文件名 + offet + length) 的映射
- 独立的 Ozone Manager 处理:
- 其他技术使用
- 使用 Ratis + Rocks DB 实现 Ozone Manager、Storage Container Manager、Data Node 元信息的高可用。
- 使用 Ratis Log 作为 WAL,同时使用内存缓存尚未写入处理完的数据,Ratis 异步写入 Rocks DB,从而提高吞吐量。
- 不支持 Erasure Coding
- Rocks DB 内部使用 Compaction 清理元信息。
Ozone Manager / Storage Container Manager:
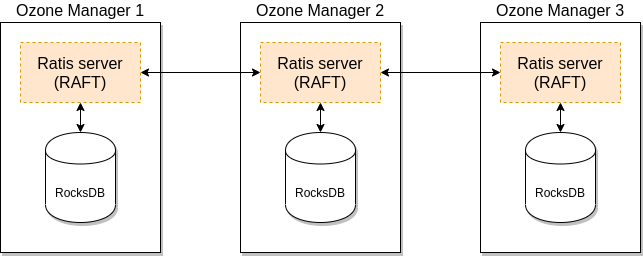 Data Node:
Data Node:

- 设计取舍
- Apache Ozone 相对 HDFS 主要优化的有两点:
- 由 OM 和 SCM 分别进行元数据管理,能提供相对 HDFS 单一 Name Node 更大的元数据处理能力。
- 用 Container 概念将多个 Block 合并起来,从而便于处理小文件。
- Apache Ozone 的架构相对于 Azure 和 GFS + Bigable 简单一些,因为在对象 key 映射到底层 Block 的这一层 Ozone 只有一个 Ozone Manager 进行处理。所以 Ozone Manager 相当于整个系统的一个单点性能瓶颈。Cloudera 做过一个测试,10亿个 key 的元数据大概占用 OM 127G SSD 的存储空间。
- Ozone 大量使用了 Rocks DB 作为底层 LSM tree 的实现,再使用 Ratis 作为共识机制的框架,也大大减少了实现的复杂度。
- Apache Ozone 相对 HDFS 主要优化的有两点:
AWS Dynamo (S3)
- 设计目标:
- 提供写入永不失败的储存系统
- 提供使用者可调整 可用性、持久性、性能的可配置储存
- 对外提供的接口:
- 类文件的 key value 储存
- 操作类型:create / delete / open / close / read / in place write / append
- 磁盘储存方案:
- 支持多种可替换的本地存储引擎,例如 Berkeley DB,MySQL,LevelDB,根据引擎不同,使用的底层数据结构有可能是 LSM tree,也可能是 B+ tree
- 每个一致性哈希环上分割的 partition 对应一组 db files
- 分布式模型:
- 基于一致哈希的去中心化模型
- 元信息管理方案:
- 哈希环上的虚拟节点与实际节点的映射哈希函数是在代码里写死的
- 大部分元信息不会变化,视为部署参数,例如:
- 一致哈希环使用的 partition size,即哈希空间分为 Q 个 partition
- 数据需要复制的份树 N
- 写入需要成功的数量 W
- 读取时需要读取副本的数量 R
- 节点的加入和退出由运维手动触发,通过节点间 gossip 的方式,由每一台节点向其他节点发送自己的变化情况,其余每个节点自己合并,从而使集群整体状态收敛到实际状态。
- 节点的临时网络波动或者掉线状态由节点的请求成功率进行统计,并在节点本身更新。如果没有跟其他节点的交互,则不会触发更新。
- 其他技术使用
- 底层的本地储存引擎一般有使用 WAL 从而保证树结构的可靠性
- 未提及 Erasure Coding,复制完整数据提供冗余。
- 不需要 GC 或者 compaction,但是在 node 数量临时或永久变化时需要 bootstrap 或者数据迁移
- 设计取舍
- Dynamo 的主要设计区别跟 GFS 和 Azure 的区别在于使用一致哈希作为分布式的模型。虽然 Dynamo 是支持 S3 的底层结构,但是并不直接提供 S3 的服务,S3 可能针对云上用户的管理需求还有其他的实现未公布出来,例如针对热点数据可能有特别的缓存机制等。由于使用基于一致哈希的分布式模型,不需要管理和访问 metadata,可以更容易地实现低延迟。
- 另一个区别是在于对写入操作的优化,GFS 和 Azure 都属于 Quorum 参数 W=N 的系统,Dynamo 为了实现写入的更高的可用性,牺牲了读取的一致性,使用更复杂的业务逻辑来实现业务上的最终一致性,常常会设置 N=3, W=2, R=2 这样的参数来降低读写延迟。
- Dynamo 的使用中并不要求完全利用磁盘的吞吐量,而重点是放在读写的延迟上,所以使用了成熟的本地储存引擎和 B+ 树,从而利用内存缓存和 WAL 实现低延迟的读写。
Ceph
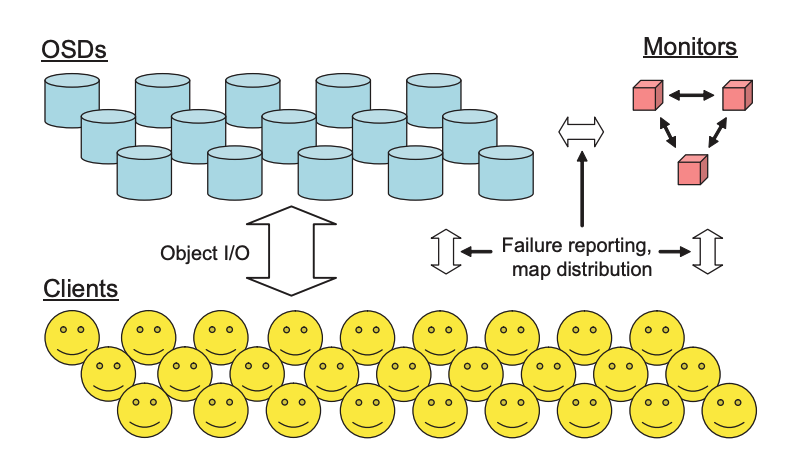
- 设计目标:
- 利用计算节点的自治性,提供去中心化的高吞吐量低延迟的对象储存,尽可能提高储存节点的 CPU 和内存利用率。
- 对外提供的接口:
- 类文件的 key value 储存
- 操作类型:create / delete / open / close / read / in place write / append
- 磁盘储存方案:
- 每个 Rados 对象存在一个单独的 XFS 文件系统的文件里
- 老版本:元信息用基于 LSM tree 的 key-value 数据库储存,老版本用 LevelDB。
- 12.0 以后的新版本:整体迁移到 BlueStore,直接访问磁盘储存介质例如SSD,NVME,元数据使用 Rocks DB 储存。
- 分布式模型:
- 基于确定的伪随机的去中心化模型
- 元信息管理方案:
- 使用 Chunk 算法将每个 key 值根据当前的集群配置映射到应该储存的节点上。Chunk 算法只需要提供:
- 集群节点所有磁盘的树状拓扑,例如每个节点下有哪些磁盘,哪些节点在同一机架,哪些节点在同一机房。
- 当前集群使用的是复制冗余还是纠错码冗余。
- 当前节点的冗余数量。
- 伪随机算法 (Uniform or List or Tree or Straw)
- Crush 算法的参数以及其他集群状态,例如节点数量,分片数量,共同组成 cluster map,每次修改均会生成新的 cluster map 版本号。
- 节点间通过多种通信保持 cluster map 的一致:
- Monitor 集群的数据更新
- 同一个分片内冗余节点间的消息传递
- 使用 Chunk 算法将每个 key 值根据当前的集群配置映射到应该储存的节点上。Chunk 算法只需要提供:
- 其他技术使用
- Rocks DB 和 Level DB 有使用 WAL
- Crush 算法同时支持复制冗余和纠错码冗余。
- 设计取舍
- Ceph 的设计中心在于尽量去中心化,从而充分利用每个储存节点的 CPU 计算资源以及自治性,避免复杂的元数据管理,整体系统的复杂度主要在负载分布算法 Crush 以及集群状态 cluster map 的更新机制。Ceph 的元数据更新机制相对于中心化的主从元数据管理复杂的多,有多条数据更新管道。
- 与 Dynamo DB 不同的地方在于:
- 使用 Rocks DB + 自定义储存介质分布方案进行底层磁盘存储,有较大空间根据具体的硬件进行优化。
- 使用伪随机的 Crush 算法而不是一致哈希作为分布负载的方案。
Minio
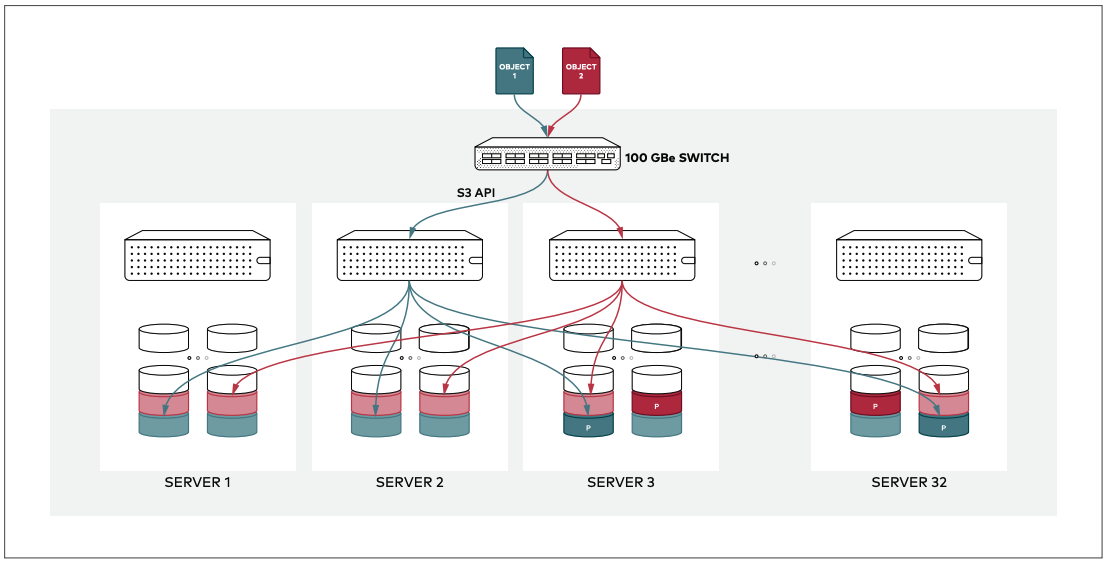
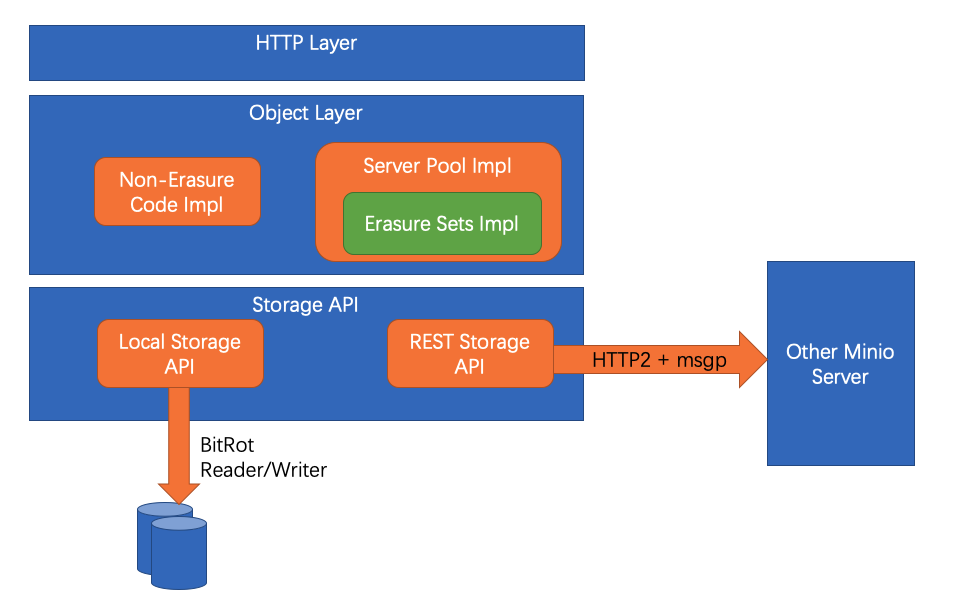
- 设计目标:
- 提供云原生的对象储存
- 提供从小规模到大规模均可用的对象储存
- 对外提供的接口:
- 类文件的 key value 储存
- 磁盘储存方案:
- 通过 Erasure coding 将文件内容拆分成小块,作为文件储存
- 单机使用时跳过 Erasure coding,直接作为文件储存
- 分布式模型:
- 作为单机使用时不进行哈希计算
- 作为集群使用时,将大集群分成若干叫做 erasure set 的分片,并根据剩余磁盘使用量随机分配新对象的储存分片。读取时遍历 erasure set 后查找对象存储位置。
- 元信息管理方案:
- 磁盘列表以及每台主机的映射关系是作为部署参数写入启动命令的
- 磁盘的在线情况以及容量使用情况通过集群内部的 heartbeat 消息传递更新
- 文件所在的对应 server pool、erasure set 以及版本记录在每个分片内部,与文件本身在同一文件夹。需要使用时遍历所有分片进行查询。
- 写入时根据每个 erasure set 的剩余磁盘使用量随机分配新对象的储存分片。
- 其他技术使用
- 未使用 WAL,利用文件系统的 atomic rename 保证读写操作的原子性和可靠性
- 利用 Erasure Coding 提供冗余
- 不需要 GC 或者 compaction
- 设计取舍
- Minio 为了实现云原生,需要满足几个条件:
- 小规模大规模皆可用:当作为开发环境时,可能只有一个可用节点,<10G 内存,同样也需要能提供完整的功能。
- 可伸缩:为了实现可伸缩,Minio 在储存层提供两种模式,单节点的非 Erasure code 模式和基于 Erasure Coding 的分布式储存。
- 将内部 API 提供出来作为 Kubernetes Operator:这个要求底层实现不依赖于操作系统或者储存介质,因为 k8s 会把部署的信息抽象隐藏,所以 Minio 并没有依赖 kernel 的特性进行实现,也没有利用 RDMA、HDD 或者 SSD 的特性进行实现或者优化。
- 容器易部署:使用主从结构这样的异构部署时,组件数量会更多,组件越多就会导致配置越复杂,在云上部署容易出错,所以使用基于哈希的模型可以简化部署方案,实现容器轻量级部署。
- 使用遍历 erasure set 查找对象储存位置的方式,避免了维护元信息表的工作,同时扩容后的机器不需要做数据迁移,但是有几个问题:
- 当集群中的 erasure set 数量变多时,P99 的延迟可能会增大,因为整体性能是由最差的 erasure set 的响应决定的。
- 如果用户使用规律由倾向性,例如新数据的读写更频繁,旧数据的读写更少,可能会导致新加入集群的 server pool 和 erasure set 的负载过高且无法调整。
- Minio 和其他系统比较不同的在于扩缩容的机制:
- Minio 不支持增加单独一台机器进行扩容,扩容的最小单位是 server pool,每个 server pool 中包含多个磁盘或者主机。这样的设计可以使每个 server pool 内部的负载分配是唯一的,但会使扩容后多个 server pool 的操作延迟增加,我认为这部分仍然有优化的空间。
- Minio 的扩缩容也要求尽量同时重启所有 server,但这会导致系统短暂的不可用。这个要求简化了启动时状态更新的逻辑,因为本质上它要求所有部署节点是同构的。
- 由于扩缩容的最小单位是 server pool,所以每个 server pool 内部的磁盘和主机需要有相同的配置,否则性能会被配置最差的一台所限制。我认为这个也可以通过负载分配算法进一步优化。
- Minio 利用的是操作系统和文件系统的 rename 操作来保证写操作的原子性,所以没有 WAL 的参与,简化了系统实现。但这也意味着在一个文件夹的文件数量过多时,会达到 Linux 同一子目录下文件数量的上限限制,这个限制需要重新编译内核才能修改。同时单目录下文件过多时,inode 会很大,可能导致文件的读写访问变慢。
- 让我很惊讶的是 Minio 基于 Linux 文件系统的实现,性能居然还可以,并没有因为 rename / create 操作而导致严重的性能损耗。
- Minio 为了实现云原生,需要满足几个条件:
储存系统设计选型
结合前面对比的情况,在设计储存系统的时候,有主要几个考量点:
- 吞吐量的重要性 vs 访问延迟的重要性
- 为了实现尽可能高的读写吞吐量,我们可以利用 LSM tree 作为磁盘的存储结构,从而尽可能利用顺序读写的性能。可以用 Level DB 或 Rocks DB 作为存储引擎。
- 如果是为了实现尽可能低的写延迟,我们可以在 LSM tree 前增加 WAL 保证可靠性,从而降低写延迟
- 如果读延迟是更重要的,可以使用 B+ 树或者哈希表作为储存引擎,可以用 MySQL 等作为储存引擎
- 如果希望同时达到读写的低延迟、高吞吐量,可以通过牺牲一定一致性从而实现:LSM tree 提供写入的持久化储存,B+ 树或者哈希表提供读取索引
- 负载均衡的灵活性 vs 部署的复杂度
- 如果希望可以更灵活地调度负载,选择主从结构作为分布式模型。
- 如果希望可以简化部署难度,可以选择哈希结构作为分布式模型。
- 二者的缺点都可以通过更进一步的细节设计缓解,所以并没有哪个特别好或者不好。
总结
这篇文章主要是为了梳理持久化储存系统设计时常用的思路和数据结构,很多限制和取舍都是由底层的储存结构特性和网络特性导致的,所以持久化的储存服务跟非持久化的缓存服务架构也会有许多不同。后续也准备看看非持久化的缓存服务的设计和实现,看对持久化的储存服务是否有借鉴参考意义。