前言
在私有化部署的系统中,系统可能会多次进行分布式组件的部署,而在私有化部署的环境中,可能没有完善的日志收集、指标收集和分析的工具,为了能便捷地进行日志、指标的收集和分析,这里提出一个简单的可复制的 ELK 日志、指标收集方案。
背景
在当前的项目中,我们已经使用了 Elasticsearch 作为业务的数据储存,同时利用 ansible、docker、jenkins 组合了一套快速部署的工具。在配置好需要部署主机的 ssh 连接信息后,我们可以通过 jenkins 一键部署一个 Elasticsearch 和 Kibana。
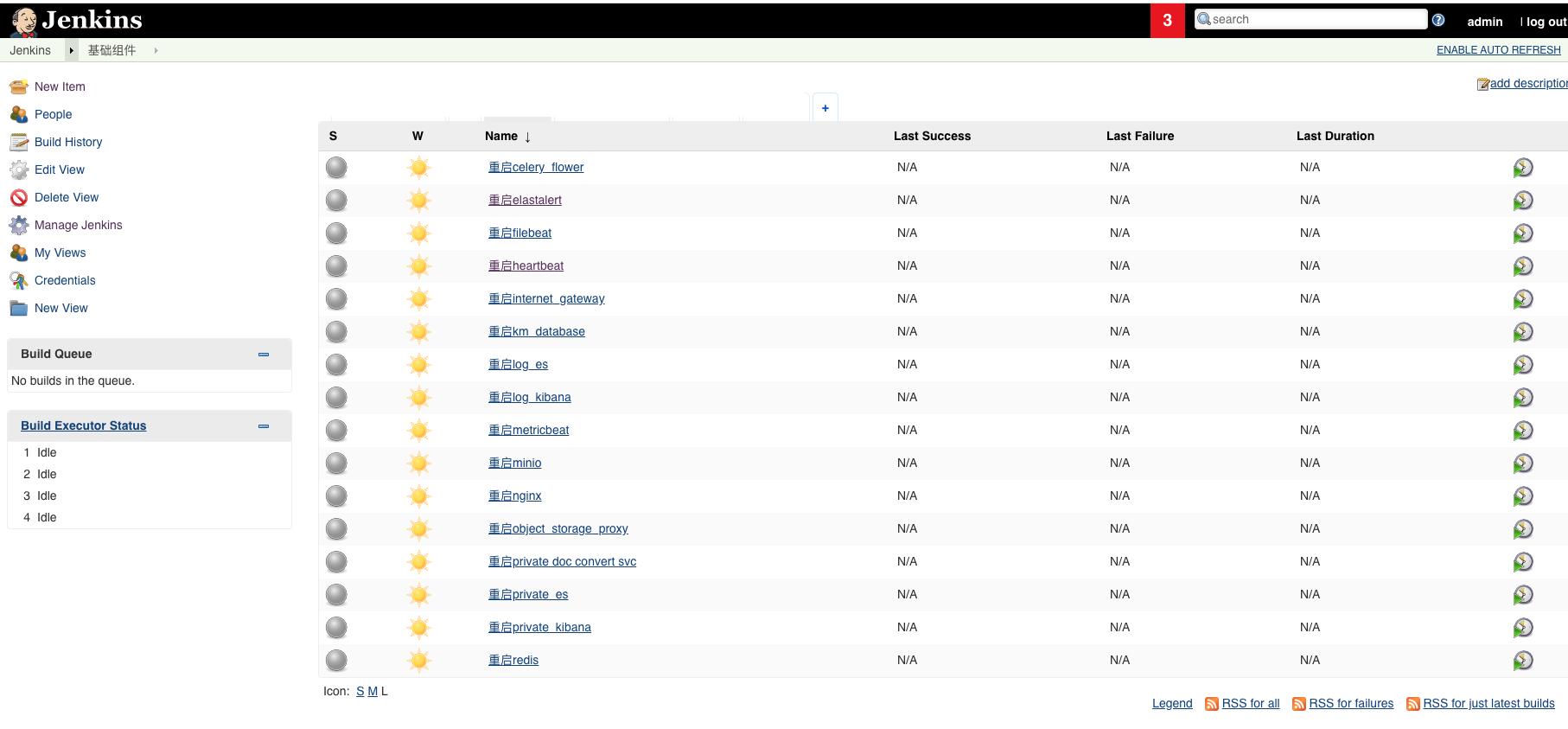
这套系统遵循以下的设计原则:
- Self-Contained Deployment:我们把所有的部署脚本、配置文件、Jenkins 任务都打包到一个标准化的 Jenkins docker 包中,只要安装到目标的环境上,即可把所有部署所需的工具都一次性带入。
- Single Source of Truth:在 Jenkins 中内嵌一个 yaml 格式的配置文件管理器,对于所有部署需要依赖的变量进行统一管理,例如xx系统后端对外暴露的端口号,只在 Jenkins 中配置一次,所有的脚本都会自动读取该变量。
- Configuration as Code, Infrastructure as Code:当所有的配置确定下来后,后续的流程理论上是可以做到全自动化的,所以所有的安装都通过脚本来完成。
需求分析
在私有化部署的环境中,日志的收集使用有几个特点:
- 需要能快速部署。由于客户的数量较多,我们需要能快速地部署监控系统,监控系统本身的运维压力需要较小。
- 部署组件要简单,且健壮性强。由于部署环境较为复杂,希望每个组件自身是健壮的,同时组件之间的交互尽量简单,避免复杂的网络拓扑。
- 功能性优于稳定性。由于日志和指标信息本身在宿主主机和应用上是有副本的,所以即时监控系统的数据丢失了,影响也不大。但是如果系统能提供更多强大的功能,对于分析是很有帮助的。
- 性能要求不高。由于私有化环境对接系统的容量和复杂度可控,可以使用单机部署,同时查询慢一些也没关系。
同时需要满足几个需求:
- 需要能采集分布式的日志,并且集中式地查看
- 需要能采集机器的基本信息,例如 CPU、磁盘,并进行监控
- 最好能采集应用的数据,例如导入数据的条目数,并进行监控
- 最好能实现异常指标的告警功能
方案分析
方案上有3个备选方案:
- 利用 ELK (Elasticsearch、Logstash、Kibana) 做整体的监控基础组件,同时使用 Elastic 新推出的 beat 系列作为采集工具。
- 利用 Zabbix、Open-Falcon 等运维监控工具进行系统基础组件的监控。同时利用自定义指标,进行数据的监控和告警。
- 利用 TICK (Telegraph、InfluxDB、Chronograf、Kapacitor) 做整体的监控基础组件。
方案2和3在需求上不能很好满足日志的收集和查看功能,所以排除掉了,目前日志方面能比较好满足需求的只有开源的 ELK 和商业化的 Splunk,由于预算原因,Splunk 也被排除了。
方案1(ELK)根据我们的需求进一步细化:
- 需要能快速部署:通过我们的 Jenkins 可以实现一键部署的功能。
- 部署组件简单:我们只部署 Elasticsearch 和 Kibana 组件,同时 Elasticsearch 本身作为最基础的组件是自包含的,不依赖任何外部组件。而我们也不使用集群,只用单机部署,保证 Elasticsearch 部署的简单和稳定。
- 功能性优于稳定性:虽然业务使用的 Elasticsearch 停留在 5.5.3 版本,我们日志采集和分析使用的 Elasticsearch 直接升级到 7.6.0 版本,同时后续的版本升级也可以较为激进,如果遇到不兼容的情况,也不需要保留已有数据,删除数据重新部署即可。
- 性能要求不高:使用单机部署,Elasticsearch 和 Kibana 部署在同一台机器上。
日志专用的Elasticsearch、Kibana、Beat
为了避免日志使用的 ES 和业务使用的 ES 在资源或者配置上发生冲突,日志专用的 ES 单独做了一个部署,使用约 3G 内存。
日志采集:
- 我们在所有相关主机上使用 ansible 部署filebeat 进行日志的采集,为了简化系统,我们也没有使用 logstash 做日志的预处理,只是简单地配置了 filebeat 的配置文件,并加入了我们的 jenkins 一键部署套件中。
日志的查看:
- 由于日志直接通过 filebeat 收集到了 es 中,我们使用 Kibana 就能直接进行查看了。
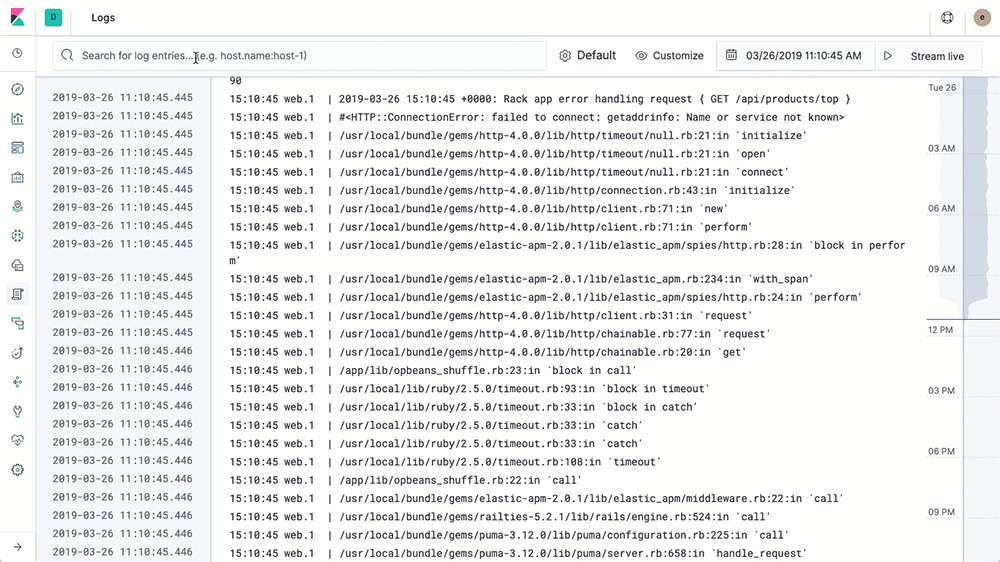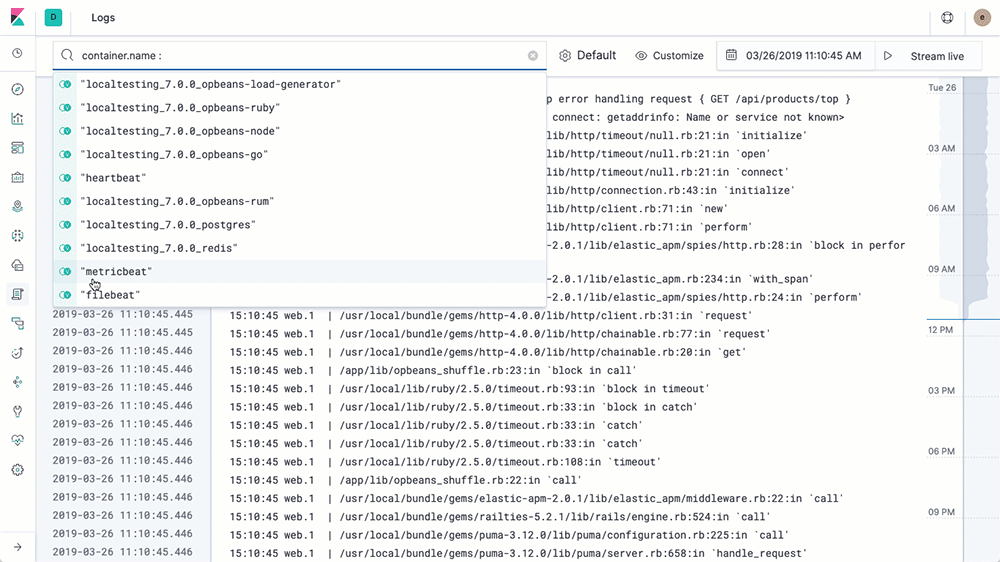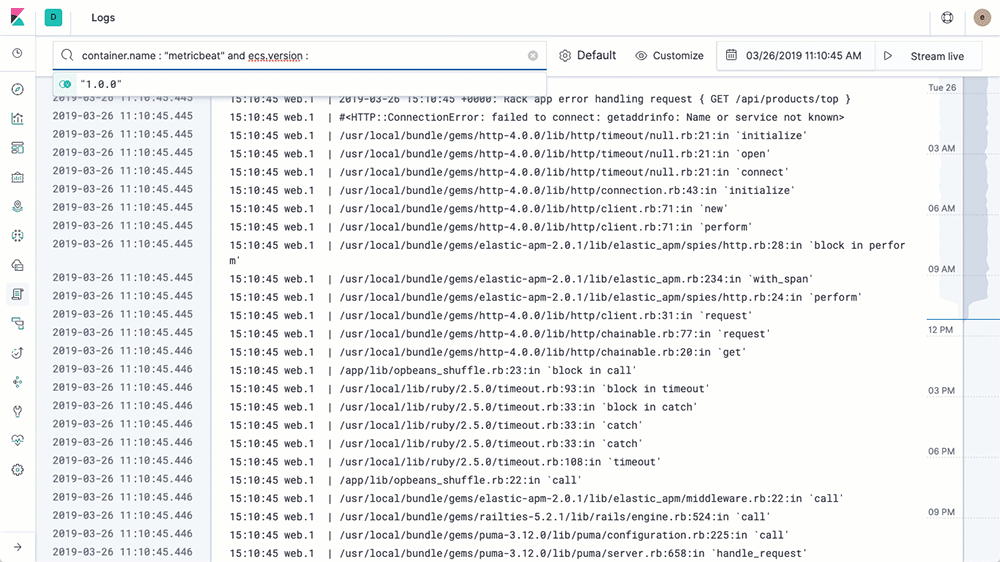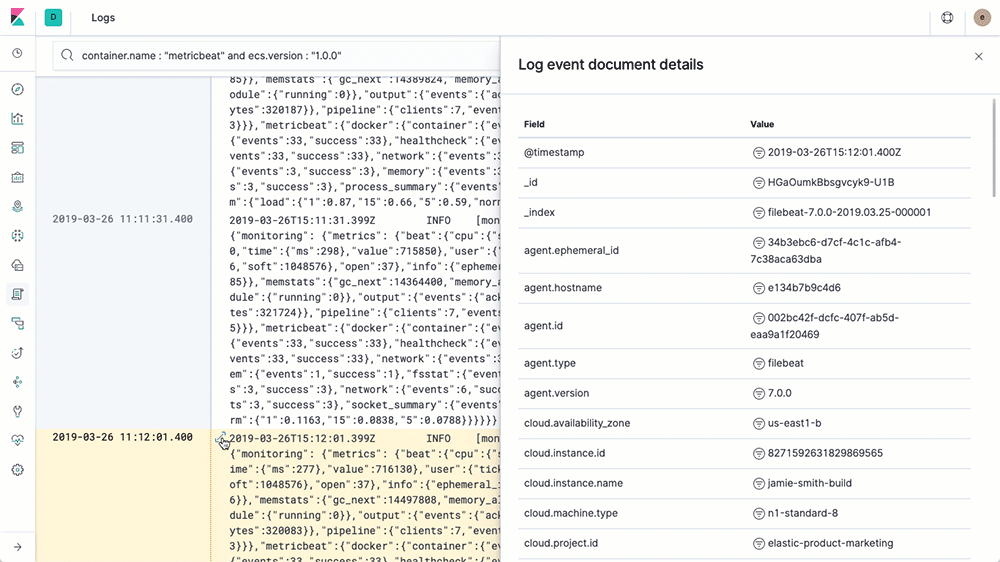
系统指标收集:
- 我们在所有相关主机上使用 ansible 部署 metricbeat 进行指标的收集,通过配置文件的配置,可以采集到 docker 的资源使用、系统CPU、内存、磁盘、网络的使用状态,同时也开放了 statsd 格式的指标收集端口。
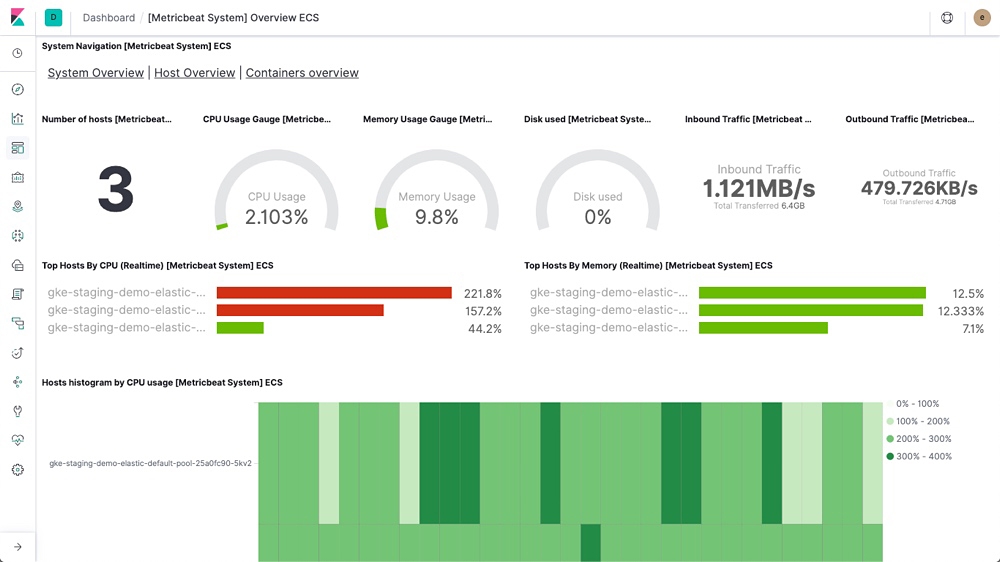
在现场状态检测:
- 我们在网关机器上使用 ansible 部署 heartbeat 进行主动的资源可用性探测,对系统相关的数据库、http服务等监控其相应状态,并将其发送至默认的 ES 储存索引中。
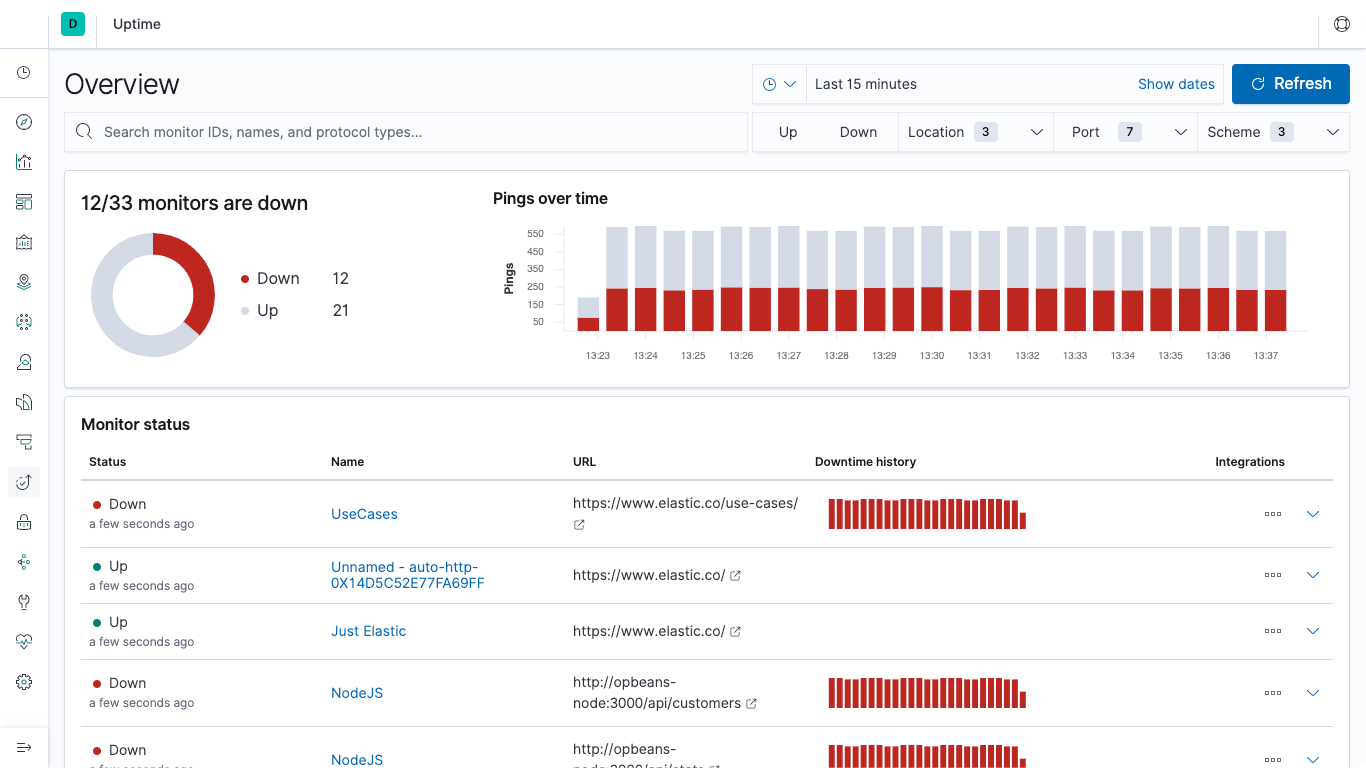
基于ES的告警
Elasticsearch 的告警是付费功能,所以这里用了一个开源的项目 elastalert 实现告警。Elastalert 是 Yelp 公司(美国的大众点评)开发的基于 python 和 Elasticsearch 的告警系统,可以对接的告警途径很多,但是大部分都是国外的工具例如Slack、HipChat、PagerDuty,所以我们目前只使用了最基础的邮件告警功能。
Elastalert 可以配置多种告警类型,例如
- 某条件连续触发 N 次(frequency类型)
- 某指标出现的频率增加或者减少(spike 类型)
- N 分钟未检测到某指标(flatline类型)等。
每个告警的配置核心其实是一个 elasticsearch 的查询语句,通过查询语句返回的条目数来进行判断。
目前我们也只使用了最基础的 frequency 类型告警。由于这个告警是针对特定几个私有化部署的系统,所以我们提前配置好了若干个告警的配置文件,在部署脚本中,如果没有特别需求,就全部复制到 elastalert 的系统中,不需要任何手工配置。
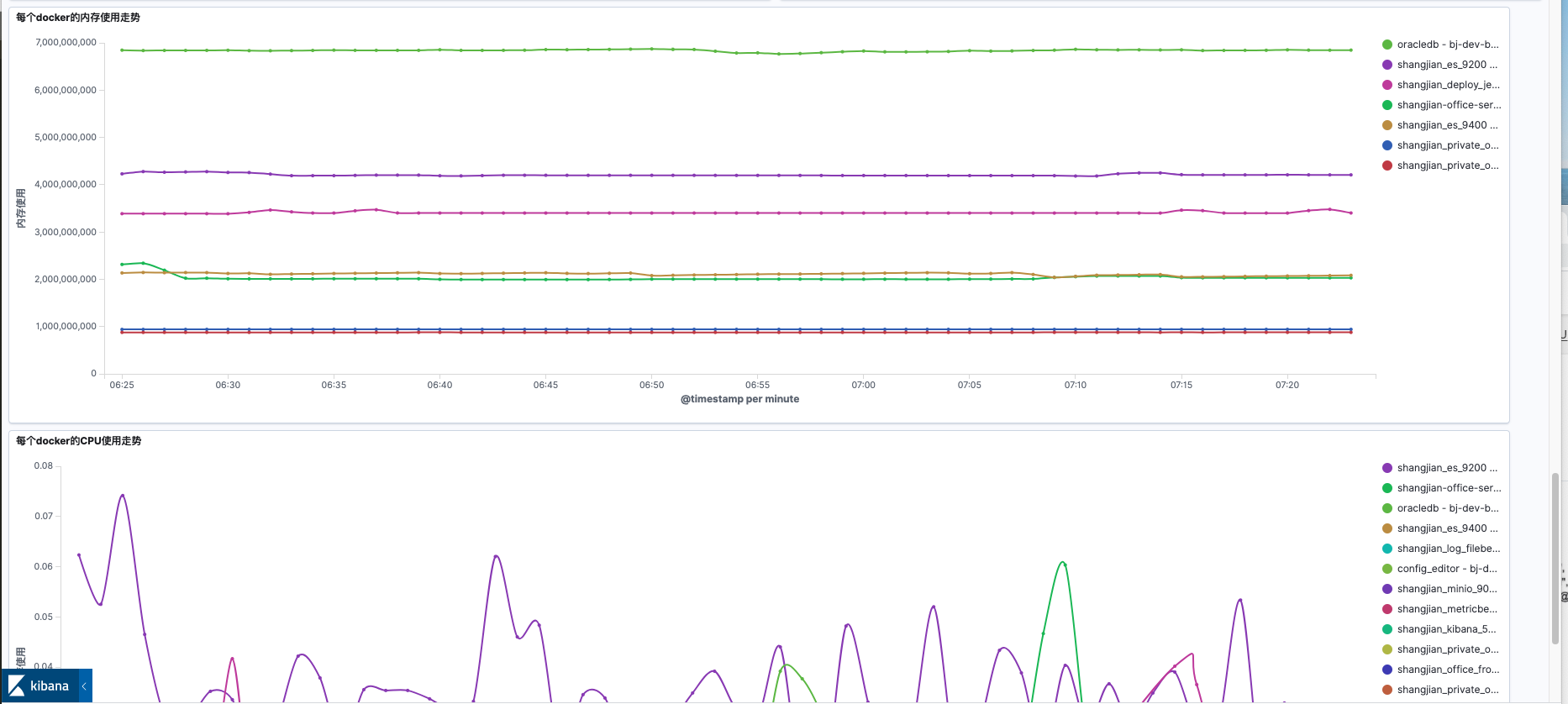
监控大盘
利用 Kibana 的可视化功能,我们可以针对每个业务系统创建一个监控大盘,直观地看到所有系统组件的情况,以及宿主主机的健康情况:

Kibana配置自动化
Kibana 当中所有持久化了的配置都是一个 Saved Object,包括:快捷搜索、监控大盘、可视化面板、索引配置。
我们在内部的测试环境中配置好了一个监控用的 Kibana 后,将配置文件通过 CI 系统定期导出储存于 git 仓库中,下一次更新基础组件时,更新脚本就会自动将对应的 kibana 配置导入到私有化部署的环境中,在部署时不需要任何手工配置,实现 Infrastructure as Code。
扩展监控范围
这套部署组件在扩展上也是有一个标准流程的。
监控更多的应用组件
当我们需要监控新增的应用组件时。
- 对于服务状态,我们可以简单地将应用组件的访问地址加入 hearbeat 的配置中,就可以在监控面板看到对应组件的状态了。
- 对于应用日志,我们可以将日志的文件路径加入 filebeat 的配置中,就可以在 Kibana 中搜索到了。
监控应用相关的指标
当我们需要监控应用相关的指标时,我们可以通过 statsd 的接口,将指标发布至 metricbeat,统一收集至 Elasticsearch 当中。 statsd 底层规则相对简单,所以在每个编程语言中都有相应的 SDK 可以直接使用,并没有复杂的依赖: https://github.com/statsd/statsd/wiki。
但是目前 metricbeat 收集来的 statsd 信息是不支持 tag 的,所以还只能做一些简单的指标收集,并不能对同一指标的不同维度做聚合分析。
增加服务 tracing
Elasticsearch 当中也带了 APM 服务  这个暂时还没有尝试接入,如果可以使用的话,是一个性能监控和分析的利器。
这个暂时还没有尝试接入,如果可以使用的话,是一个性能监控和分析的利器。
总结
私有化部署的环境中,日志的收集和监控不像互联网产品一样需要较强的性能和可扩容性,开箱即用和功能的强大就较为重要。7.6.0 版本的 Elasticsearch 和 Kibana 在这方面能很好地满足需求,只需要对部署流程进行标准化,并提前准备好配置文件,就可以在半小时内搭建好一整套监控体系。