起因
在数据采集和分析的流程中,目前有3个痛点不好解决:
- 数据采集之后是以多个小 json 文件储存在类似 AWS S3 的对象储存中的,当我们要核验数据的特征,例如最大值,数据总数之类的,需要使用 MapReduce 或者 spark 才能实现,而这个操作门槛相对较高。并且由于数据是以多个小文件的形式存在,批处理脚本的执行效率低,每次都需要较长时间才能完成一个简单的数据查询。
- 数据清洗的时候不了解数据特性,例如空值,异常值的情况,所以容易在清洗过程中欠缺对异常情况的处理。
- 数据分析的迭代周期长,出了问题回溯困难。因为统计需要使用专业的数据处理脚本,所以需求提出之后,需要经过代码实现,测试,批量执行之后才能看到结果,迭代周期往往以天计算。同时某个数据的统计值与预期不符时,缺少合适的工具帮助回溯到原始数据。
这里使用的是阿里云 Data Lake Analytics 服务帮助解决这个问题。同时用阿里云的 OSS 作为数据源储存。
Data Lake Analytics 将一些简单的 ETL 任务封装成 SAAS 服务了,所以绝大部分的操作是在阿里云的控制台上执行的。
简化将小文件合并成大文件的过程
首先,我们来解决痛点1。
对于小文件查询慢的问题,传统的解决方法是写一个 spark 的数据清洗脚本来将其转为 parquet 格式,然后再用 zepplin 之类的工具进行查询分析。
Data Lake Analytics 的处理分成以下几个步骤:
建立一个外表连接到需要处理的 OSS 路径。
这里可以使用阿里云的建表向导来进行。

填入几个关于数据源的信息后,会自动生成一个建表的 schema。

这里建议大家手动审核调整一下建表的 sql,然后在 sql 界面进行建表。
使用 Data Lake 的 MySQL 接口连接其数据库
在阿里云控制台可以获取到连接的参数信息。建议根据 文档 配置子账号并用子账号创建新表。
连接上之后,我们就可以用刚才阿里云生成的建表 sql 创建一个新的外表了。
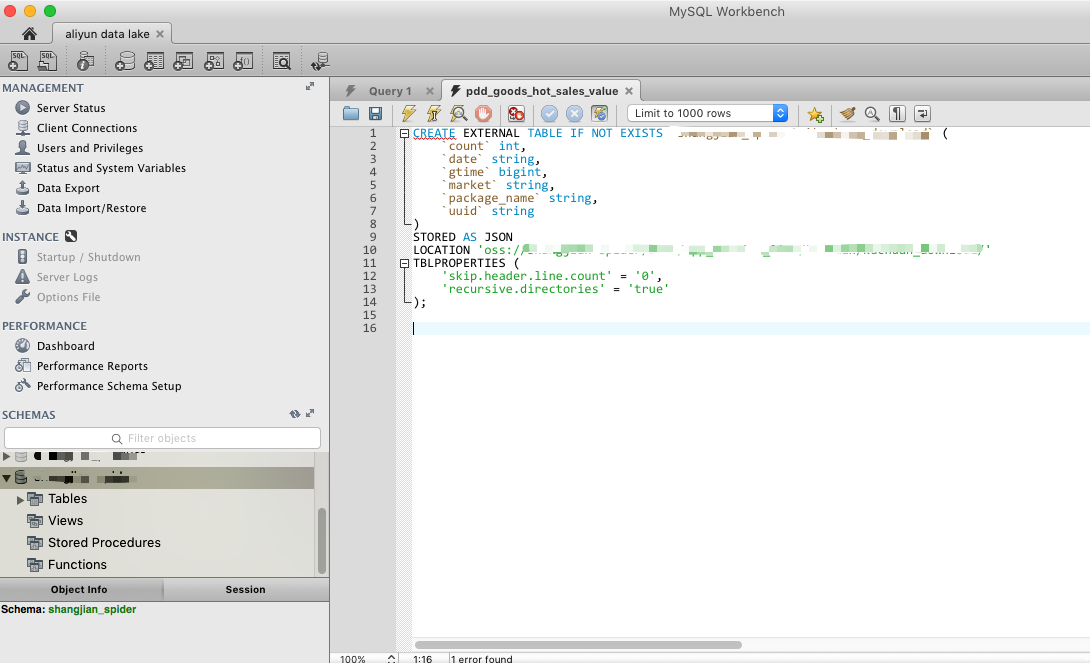
建立 Parquet 格式的外表
使用前面阿里云建表向导提供的建表 SQL,我们可以做一些修改,例如将 STORE AS JSON 改为 STORE AS PARQUET 然后建立一个指向新的 OSS 路径的外表。
然后我们可以使用下面的 SQL 将 JSON 格式的文件导入到 PARQUET 格式的文件中去,完成小文件合并的任务。
/*+run_async=true*/
INSERT INTO parquet_table SELECT * FROM json_table
记得加上面的 /*+run_async=true*/ 标注,因为这个执行过程比较久,将其设置为异步执行可以避免由于 mysql 客户端超时导致的任务失败。
在Parquet文件上进行数据特性分析
当我们将数据从 json 文件插入至 parquet 文件后,我们就可以从 parquet 文件对应的表进行 sql 查询了。由于文件已经被合并成大的 parquet 文件,查询性能也会大大提高。
回溯问题文件
当我们发现数据的统计值不符合我们的预期时,往往需要回溯寻找出问题的原始数据是什么,Datalake 也是做这类工作的一个利器。
当我们使用 OSS 作为外表进行查询时,我们可以使用 $path 获取外表数据源的文件名称。
SELECT $path, * FROM json_table
如果你看到这里,一定是真爱!欢迎看看我的其他 blog。O(∩_∩)O